
HikariCP 를 조사하면서 정확히 어떤 역할을 하는지 조사해 봤습니다. 먼저 HikariCP 를 알기 전에 DB Connection 과 CP 가 무엇인지 알아야 합니다.
DB Connection
사용자가 자신의 이름과 자기소개, 사진을 보기 위해 ‘내 프로필’ 버튼을 클릭합니다. 클릭하게 되면 내 정보가 서버로 넘어가게 되는데, 서버는 넘어온 내 정보를 가지고 이름과 자기소개, 사진을 찾아야 합니다. 그러기 위해선 DB(데이터베이스) 에 접근해야 하는데, 접근하기 위해선 DB Connection 이 필요합니다.
DB Connection 은 서버와 DB 를 연결해주는 개념이라고 보면 됩니다. 서버와 DB 를 연결해주는 부분은 굉장히 비싼 비용을 주고 있습니다. 비싼 비용을 주면서 연결했지만 원하는 데이터, 즉 이름과 자기소개, 사진을 가져오고는 Connection 을 끊어버리죠.
사용자가 많지 않은 상황이면 굳이 신경쓸 필요는 없을 겁니다. 하지만 사용자가 수백 수천명일 경우는 어떨까요? Connection 비용이 비싼 만큼 서버와 DB 는 점차 힘겨워 할 겁니다.
이 같은 문제를 해결하기 위해 CP (Connection Pool) 가 나옵니다.
Connection 은 왜 비싼거지?
CP 로 넘어가기전에 Connection 은 왜 비싼걸까? 라는 의문이 생기실 겁니다. 저도 왜 비싼지에 대해 의문을 가졌기에 한 번 찾아봤습니다. 이유는 서버와 DB 가 Connection 을 가져오기 위해 TCP 통신을 한다는 겁니다. TCP 통신은 이렇습니다.
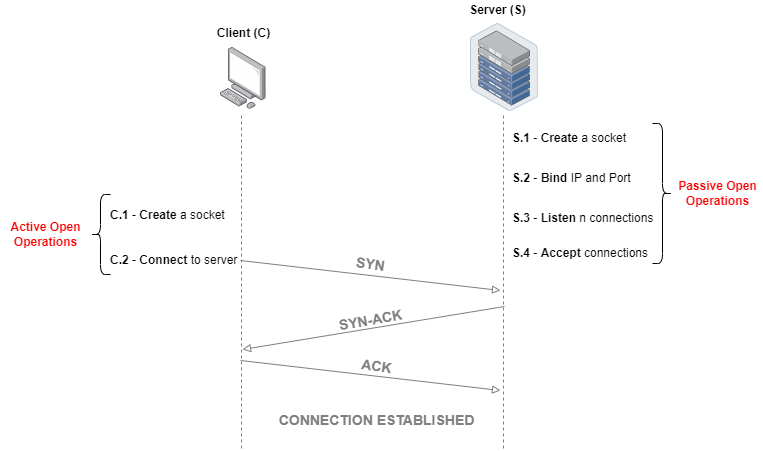 출처 : https://www.baeldung.com/cs/tcp-active-vs-passive
출처 : https://www.baeldung.com/cs/tcp-active-vs-passive
개념 이해를 이해 이미지가 필요합니다. Client 는 서버, Server 는 DB 라 생각하고 읽으시면 더욱 편합니다. 서버는 DB 와 연결하기 위해 Connection 을 진행합니다. Connection 을 하기 위해 URL, ID, PW 정보를 입력해야 합니다. 어디서 많이 본 형식같죠? 마치 네이버나 카카오에 로그인 할 때 입력하는 화면 느낌일 겁니다. 사실 거의 똑같다고 보시면 됩니다.
연결을 시도하면 서버가 DB 로 요청을 보내는데 SYN 패킷을 보내게 됩니다. 수신 받은 DB 는 서버에서 요청한 데이터와 함께 SYN, ACK 패킷을 응답하게 되고 서버는 Connection 이 정상적으로 됐는지 확인 응답 패킷(ACK)을 DB 에게 보냅니다. 이 과정을 3-Way-Handshake 라고 합니다.
만약 서버에서 확인 응답을 보내지 않는다면 DB 는 다시 한 번 응답을 받기 위해 확인 요청 패킷을 보내게 됩니다. 이렇게 해야지 정상적으로 연결됐다고 인식할 수 있습니다. 보내고 받기만 하는 줄 알았는데 검증까지 해야 된다니 비용이 많이 든다고 할 수 밖에 없군요.
이게 오래 걸리는 작업인가? 라는 의문이 생길 수 있습니다. 공신력을 얻기 위해 MySql 공식 홈페이지를 참고한 결과.
 출처 : https://dev.mysql.com/doc/refman/8.0/en/insert-optimization.html
출처 : https://dev.mysql.com/doc/refman/8.0/en/insert-optimization.html
괄호 안에 들어있는 숫자가 작업 비용의 비율이라고 볼 때 Connecting 이 가장 높은걸 볼 수 있습니다. 이렇게 비용이 높은 작업을 사용자가 요청 할 때 마다 실행한다면 과연 비용이 얼마나 소비되고 있을까요?
CP (Connection Pool)
CP(Connection Pool) 는 서버와 DB가 연결하면서 생긴 Connection 을 저장하는 공간입니다. 조금 더 풀어서 설명하자면, 미리 만들어 놓은 Connection 이 존재합니다. Connection 을 저장해 놓는 공간을 Connection Pool 이라고 합니다. 사용자가 내 정보를 조회하기 위해 서버에 요청하면 서버는 내 정보를 갖고 DB 에 접근해야 하는 상황입니다.
앞서 말씀드렸다시피 Connection 이 필요한 부분이기 때문에 Connection 을 만들려고 하지만, Pool 안에 만들어진 Connection 이 있으므로 가져다 사용하기만 하면 됩니다.
여기까지 이해 된다면 CP의 역할은 어느정도 이해했다고 보면 됩니다. 다만 CP 도 여러 종류가 존재합니다. HikariCP, tomcat-jdbc-pool, commons-dbcp 등 여러가지 CP 가 존재하는데, 이 중 저희가 알아 볼 것은 HikariCP 입니다.
여러 종류가 있지만 굳이 HikariCP 를 알아보는 이유는 Spring Boot 2.x 버전 기준으로 기본 CP 가 바뀌었기 때문입니다.
- Spring Boot 1.x 기본 Connection Pool [ tomcat-jdbc-pool ]
- Spring Boot 2.x 기본 Connection Pool [ HikariCP ]
HikariCP 가 뭐지?
위에 작성한 내용을 이해했다면 한 문장으로 설명이 가능할 것 입니다. 말 그대로 DB Connection 을 Connection Pool 로 관리해주는 역할입니다.
HikariCP 는 왜 사용하는 거지?
이미 여러 훌륭한 Connection Pool 이 존재합니다. 굳이 HikariCP 만이 아니라 환경과 상황에 따라 CP 의 선택 기준이 달라질 수 있다는 점 꼭 참고하시고 ‘꼭 HikariCP 를 사용해야한다!’ 내용은 아닙니다.
굳이 HikariCP 를 사용하는 이유는 첫 번째로 앞서 말씀드렸다시피 결론적으론 Spring Boot 에서 기본적으로 제공하는 Connection Pool 이기 때문입니다. 두 번째로 각 벤더사 별로 Connection Pool 의 성능 지표가 존재하는데 HikariCP 가 월등히 높았습니다.
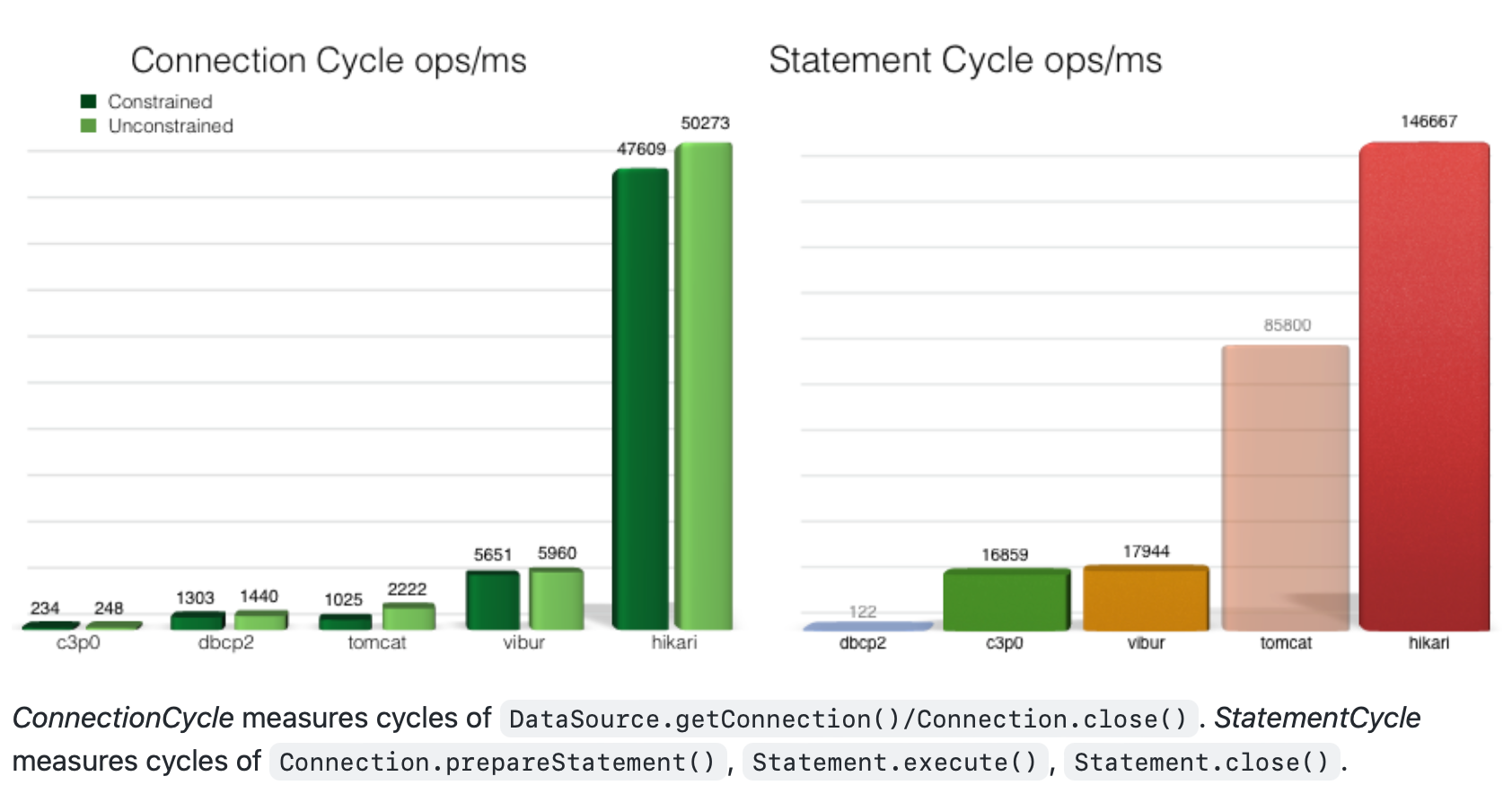 출처 : https://github.com/brettwooldridge/HikariCP-benchmark
출처 : https://github.com/brettwooldridge/HikariCP-benchmark
이미지 그래프 아래 내용에 따르면
하나의 연결 주기는 DataSource.getConnection()/ Connection.close()로 정의됩니다. 하나의 Statement 주기는 Connection.prepareStatement(), Statement.execute(), Statement.close()로 정의됩니다.
서버와 DB 가 연결이 하면서 발생하는 성능이 각 벤더사 별로 극명한 차이가 나는걸 볼 수 있습니다. 또한 쿼리 정의, 실행, 종료 까지 포함한 성능 또한 극명한 차이가 있음을 확인 할 수 있습니다.
HikariCP 는 어떻게 사용하는 거지?
Spring Boot 2.x 버전 이상부터 HikariCP 가 기본으로 설정 돼 Spring Boot 프로젝트를 생성하면 자동으로 구성되어 있는걸 볼 수 있습니다. 아래 이미지는 프로젝트를 직접 만들어 라이브러리를 확인한 이미지 입니다.

Spring Boot 라이브러리 목록에 존재하는 HikariCP
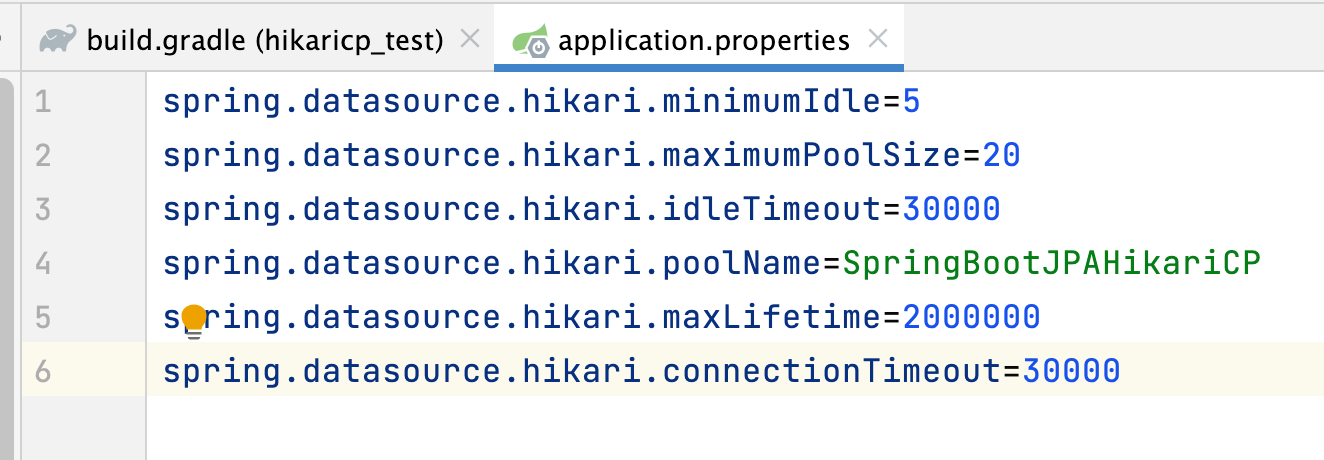
application.properties 에서 HikariCP 설정
서버와 DB를 연결하기 위해 JDBC (Java DataBase Connection) 가 필요합니다. 각 DB 벤더사 별로 서버와 연결할 수 있는 JDBC 라이브러리를 갖고 있어서 벤더사에서 제공하는 JDBC 를 의존성에 등록해야 합니다. 따라서 각자 환경에 구성된 DB 벤더사를 확인하고 의존성을 등록하면 됩니다.
저는 로컬 환경에 MySql 을 설치한 상태이므로 MySql JDBC 의존성을 추가할 겁니다.
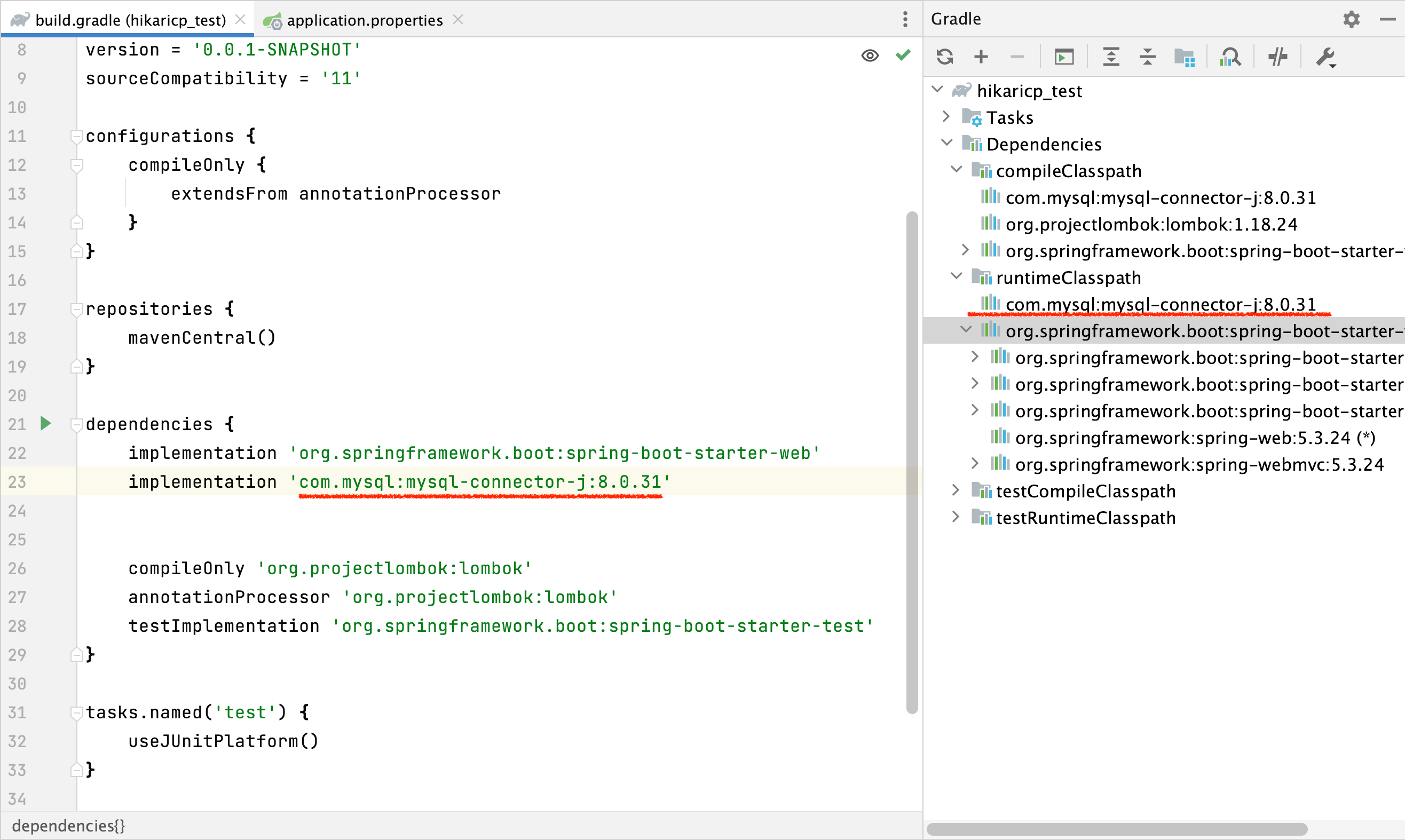
해당 라이브러리를 추가하면 오른쪽 창에 com.mysql:mysql-connector-j:8.0.31 확인 할 수 있습니다.
spring.datasource.url=jdbc:mysql://localhost:3306
spring.datasource.hikari.username=root
spring.datasource.hikari.minimumIdle=5
spring.datasource.hikari.maximumPoolSize=20
spring.datasource.hikari.idleTimeout=30000
spring.datasource.hikari.poolName=SpringBootJPAHikariCP
spring.datasource.hikari.maxLifetime=2000000
spring.datasource.hikari.connectionTimeout=30000
application.properties 해당 파일을 설정해줍니다. HikariCP 환경을 설정해주는 부분이라고 보시면 됩니다.
왜 안되지..?
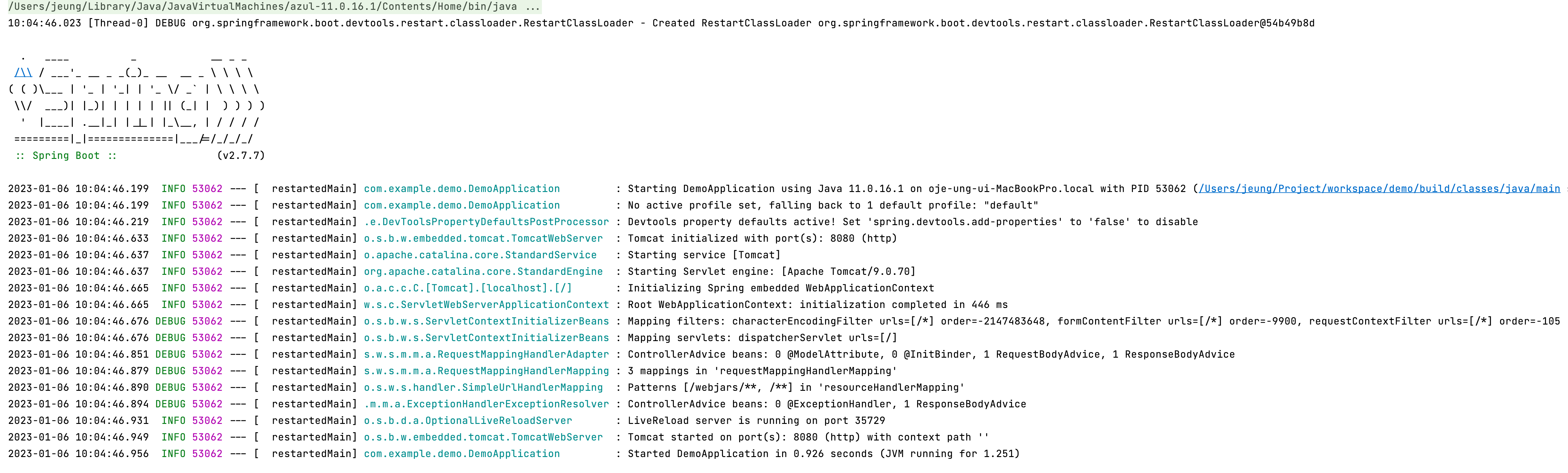 HikariCP 를 적용했지만 보이지 않는 HikariCP….
HikariCP 를 적용했지만 보이지 않는 HikariCP….
분명 서버를 실행하면 로그에 Hikari Pool Start 라는 로그가 나타나야 합니다. 하지만 서버를 실행할 때 반응이 없어보입니다. 검색해서 찾아봤지만 다른 블로그와 차이점은 application.propertse 와 application.yml 의 차이만 보일 뿐이군요. 물론 build.gradle 에도 차이가 있지만, 이미 Spring Boot 서 기본적으로 제공해주는 것으로 충분하기 때문에 문제 될 게 없어 보입니다.
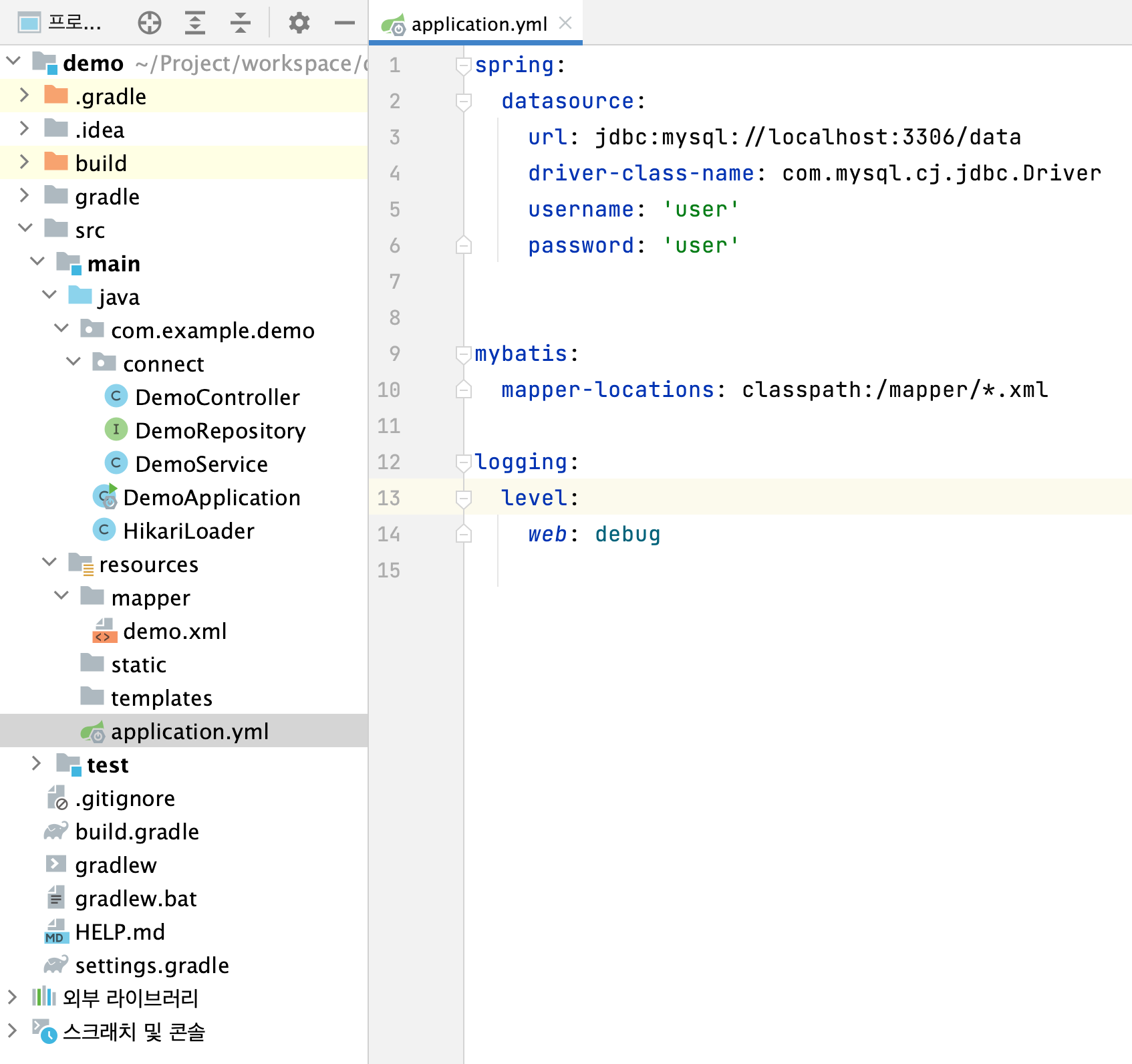
프로젝트에 문제가 생긴게 아닐까 하고 새로 생성했습니다. 확장자를 yml 로 변경하고, DB 에 스키마와 계정까지 새로 생성해서 환경설정 까지 했지만, 동일하게도 Pool Start 라는 log 는 보이지 않았습니다.
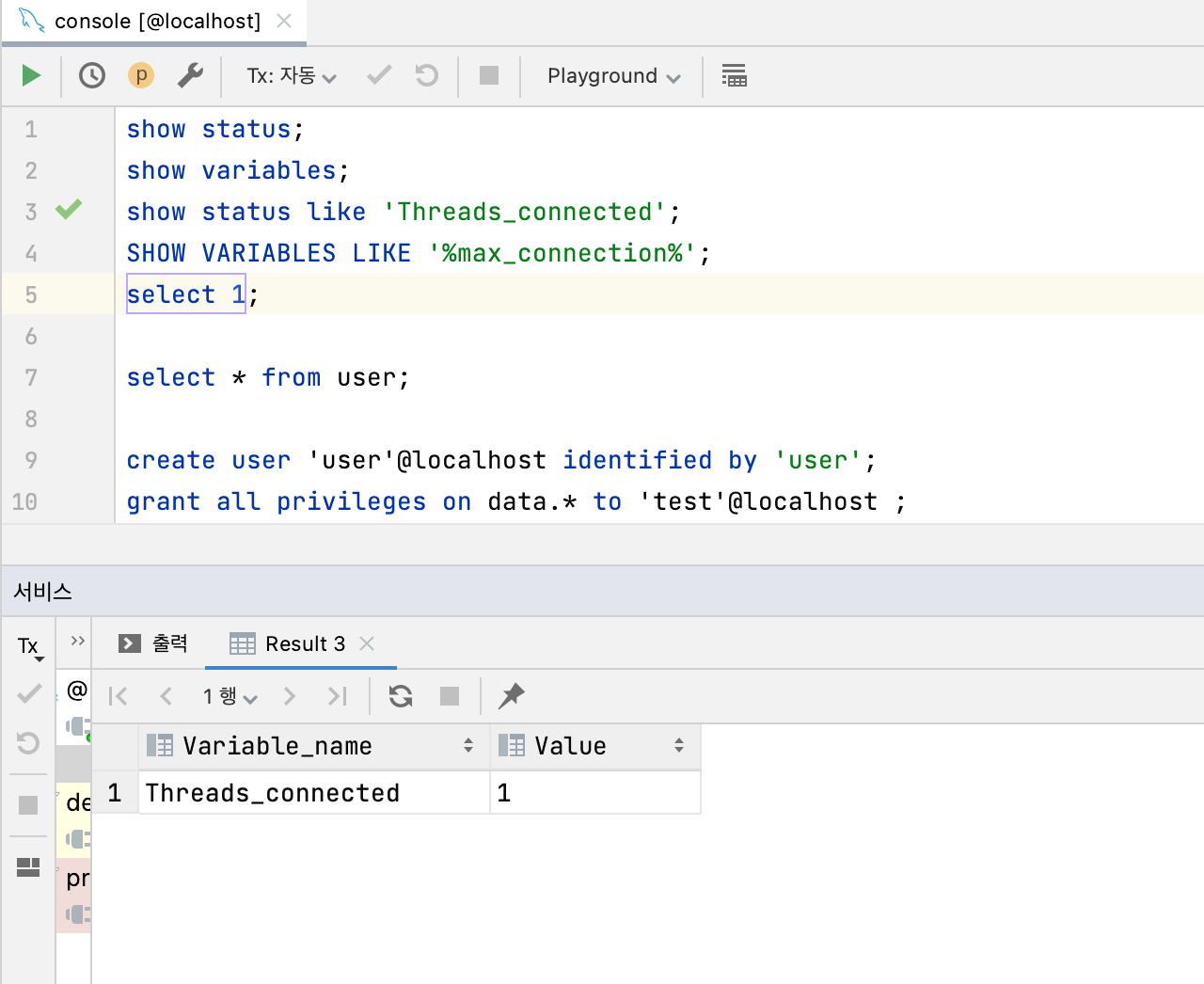 DB 조회로 연결되어 있는 Connection 개수 확인
DB 조회로 연결되어 있는 Connection 개수 확인
혹시 서버가 실행되면서 log 에 표출 안 할 뿐이지 사실 Connection Pool 에 생성 된 게 아닐까? 라는 희망을 갖고 DB 로 직접 조회 해 봤습니다.
SHOW STATUS LIKE ‘Threads_connected’ 쿼리를 실행하면 Thread 와 연결된 Connection 개수를 확인할 수 있습니다. 확인해 봤지만 연결은 되어있지 않았습니다.
연결이 되어있는지 안되어있는지 어떻게 알지? 그건 HikariCP 기본 설정값을 통해 확인할 수 있습니다. HikariConfig.java 파일을 열어보면 기본값으로 설정된 걸 확인할 수 있습니다.
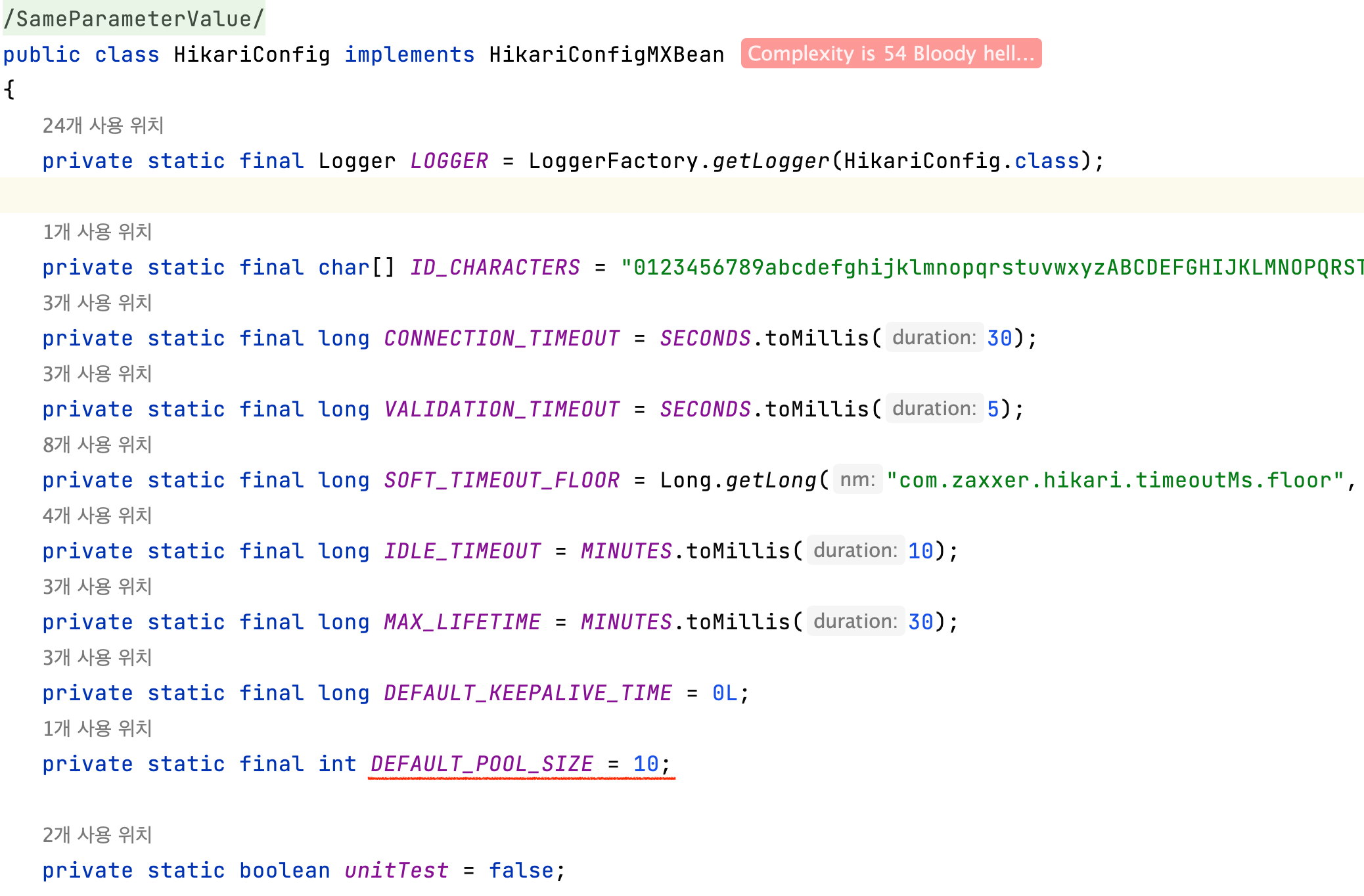 HikariConfig.java 에서 설정된 기본값
HikariConfig.java 에서 설정된 기본값
HikariCP 를 구성하게 되면 기본 설정이 존재하기 때문에 각 서버 환경에 따라 설정을 변경하며 사용합니다. 이어서 기본 Pool Size 가 존재하기 때문에 서버가 실행되면 Connection 수 가 10 개 이상이어야 합니다. 하지만 여전히 1개 보이는 건 ‘내가 뭔가 모르는 부분이 있구나.’ 직감했습니다.
게으른 초기화?
게으른 초기화는 객체를 사용하기 전 까지 준비나 실행을 하지 않겠다. 즉 사용해야지만 준비와 실행을 진행시킨다고 보시면 됩니다. 갑자기 이런 개념이 등장한 이유는 바로 HikariCP 가 게으른 초기화 (Lazy initialization) 를 보여주고 있습니다. 그 이유는 서버 재 시작할 때 느려지기도 하고 메모리 또한 절약하기 할 수 있기 때문입니다.
정상적으로 작동되는지는 Mybatis 를 설정하고 나서 알게 됐습니다. Mybatis 는 DB 에 저장된 데이터를 더 편리하게 조회하도록 라이브러리로 build.gradle 를 추가하고 Mapper 를 만들어야 사용이 가능합니다. 중점은 HikariCP 이니 Mybatis 는 추후에 다시 다루는 걸로…
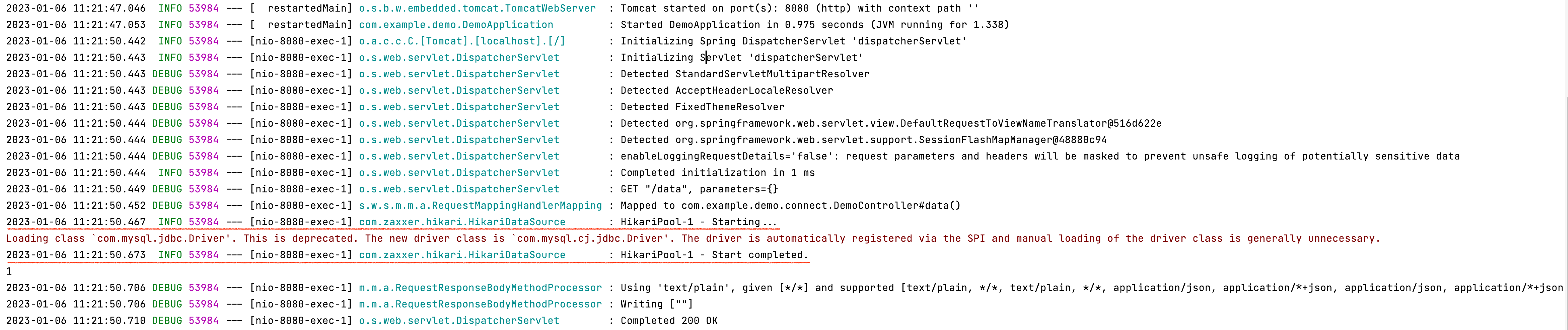 비로소 나온 Hikari Start
비로소 나온 Hikari Start
DB Connection 이 한번이라도 발생해야지 비로소 HikariCP 가 확인이 됐습니다.
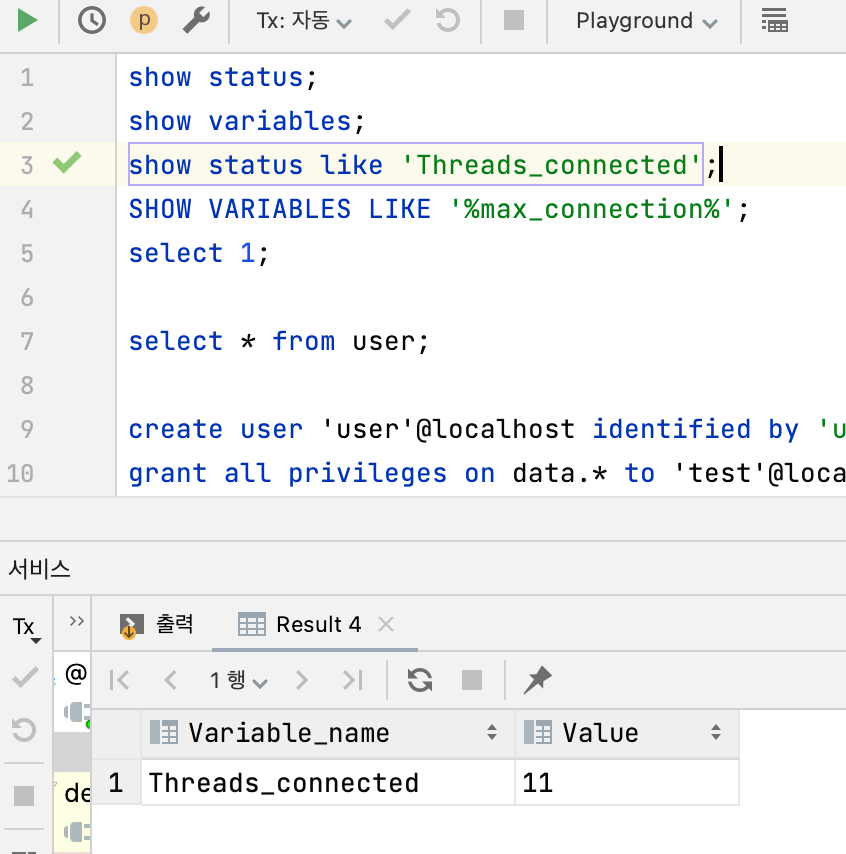 조회 결과 Connection 10 개 이상 확인
조회 결과 Connection 10 개 이상 확인
그렇다면 분명 서비스를 재 시작 할 때 누군가 DB Connection 을 한 번 이라도 시도해야 생성 될 겁니다. 앞서 말씀드렸다시피 Connection 이 느린 이유를 말씀 드렸는데 이런 현상을 어떻게 개선 할 것인지는 추가적인 학습이 필요하겠군요.
추가) 확인해보니 JPA 의존성을 추가해주면 Hikari Start 라는 문구가 나옵니다. 무엇 때문에 가능한지 이 부분을 더 학습해봐야겠습니다.
Pool Size 는 어느정도가 적합하지?
Pool Size 를 통해 Connection 개수를 미리 만들어놓수 있습니다. HikariCP 에서 기본적으로 설정된 개수를 개발자 마음대로 수정할 수 있습니다. 하지만 의미 없이 많이 만들어 놓으면 그 만큼 리소스를 사용하기 때문에 메모리 낭비가 생깁니다.
HikariCP 공식 문서에선 Pool Size 를 계산하는 방법을 제공해주고 있습니다.
 출처 : https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing#the-formula
출처 : https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing#the-formula
출처에 들어가보면 1 Connection = ((core_count) * 2) + effective_spindle_count 계산식이 존재합니다. 번역기를 돌려보면 이렀습니다.
수년 동안 많은 벤치마크에서 꽤 잘 유지된 공식은 다음과 같습니다. 최적의 처리량을 위해서는 활성 연결 수가 어딘가에 있어야 합니다. ((core_count * 2) + effective_spindle_count)에 가깝습니다. 코어 수는 다음을 포함하지 않아야 합니다. 하이퍼스레딩이 활성화된 경우에도 HT 스레드. 유효 스핀들 수는 다음과 같은 경우 0입니다. 활성 데이터 세트는 완전히 캐시되고 실제 스핀들 수에 근접합니다. 캐시 적중률이 떨어지기 때문입니다. …에 대한 분석은 아직 없습니다. 공식이 SSD와 얼마나 잘 작동하는지.
그게 무슨 뜻인지 아세요? 하나의 하드 디스크가 있는 작은 4코어 i7 서버는 9 = ((4 * 2) + 1)의 연결 풀을 실행해야 합니다. 좋은 어림수로 10이라고 부르세요. 낮아 보이나요? 시도해 보세요. 이러한 설정에서 6000TPS로 간단한 쿼리를 실행하는 3000명의 프런트 엔드 사용자를 쉽게 처리할 수 있을 것입니다. 부하 테스트를 실행하면 해당 하드웨어에서 연결 풀을 10을 훨씬 넘어서 푸시함에 따라 TPS 속도가 떨어지기 시작하고 프런트 엔드 응답 시간이 올라가기 시작하는 것을 볼 수 있습니다.
요약하자면 이렇습니다. core_count 는 서버에 장착된 CPU 코어 수를 뜻하고 effective_spindle_count 하드 디스크의 개수를 의미합니다. core_count 이 부분은 정확히 이해가 되지만 effective_spindle_count 이 부분이 확실치 않습니다. 이해한 바로는 하드 디스크 하나 당 처리할 수 있는 요청은 1개 라고 합니다. 기본적으로 DB 가 처리할 수 있는 동시 I/O (Input / Output) 요청 수를 말한다고 합니다. 따라서 16개 가 있다면 동시에 16개 의 I/O 요청을 처리할 수 있다는 의미죠. 이 부분은 조금 더 공부가 필요할 것 같습니다…
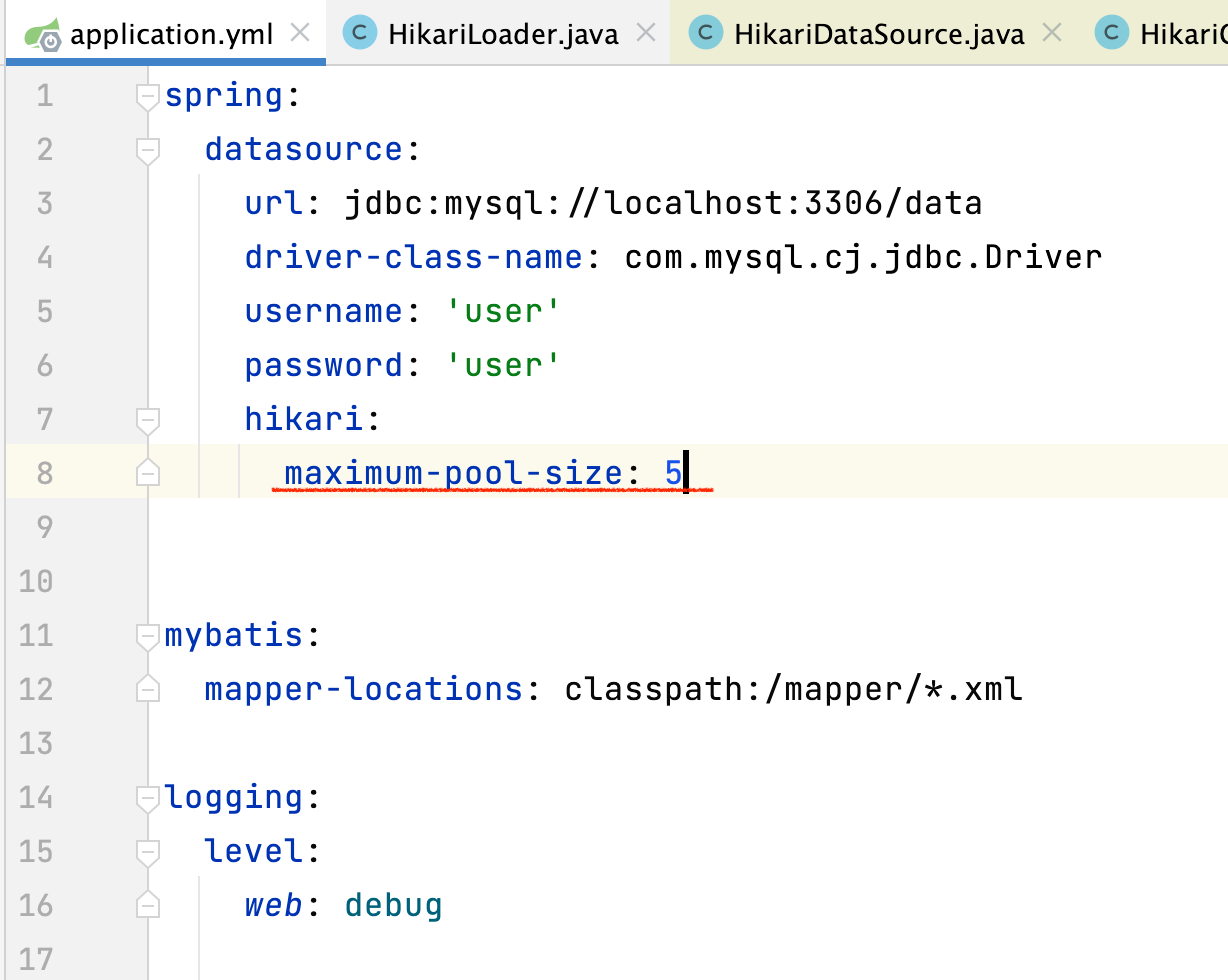 maxinum-pool-size 설정
maxinum-pool-size 설정
- core_count : CPU 코어 개수
- effective_spindle_count : 하드 디스크 개수(?)
따라서 만약 코어가 2개이고 DB 가 1개 일 경우 (2 * 2) + 1 = 5 이며 Connection Pool Size 는 5개가 되겠네요.
총평
이렇게 Connection Pool 과 HikariCP 에 대해 알아봤습니다. 이렇게 공부한 내용을 정리하면서 블로깅 하는게 쉽지않네요. 다른 분들이 읽을 수 있도록 잘 풀어서 설명하는 것과 가독성을 높이기 위해 단어 선택과 적절한 그림을 섞는 방법… 쉽지 않군요.
아직까지 부족한 부분들이 존재합니다. 스스로 부족하다고 느꼈던 부분은 ‘HikariCP 왜 사용하는거지?’ , ‘HikariCP 는 어떻게 사용하는거지?’ , ‘Pool Size 는 어느정도가 적합하지?’ 라는 부분을 좀 더 학습해야지 않을까 싶습니다. 그리고 CP 중 가장 성능이 좋은게 무엇인지 실제로 부하테스트를 통해 눈으로 직접 봤으면 했던 부분까지도 말이죠.
다음부터는 부족한 부분을 채우고 블로깅을 해봐야 할 것 같습니다. 봐 주신 분들께 감사드리고 궁금한 부분이나 피드백 하실 부분이 있다면 댓글로 남겨주시면 감사드리겠습니다!