
Spring Batch - Flow
Spring Batch 에서 Flow 대해 알아보겠습니다.
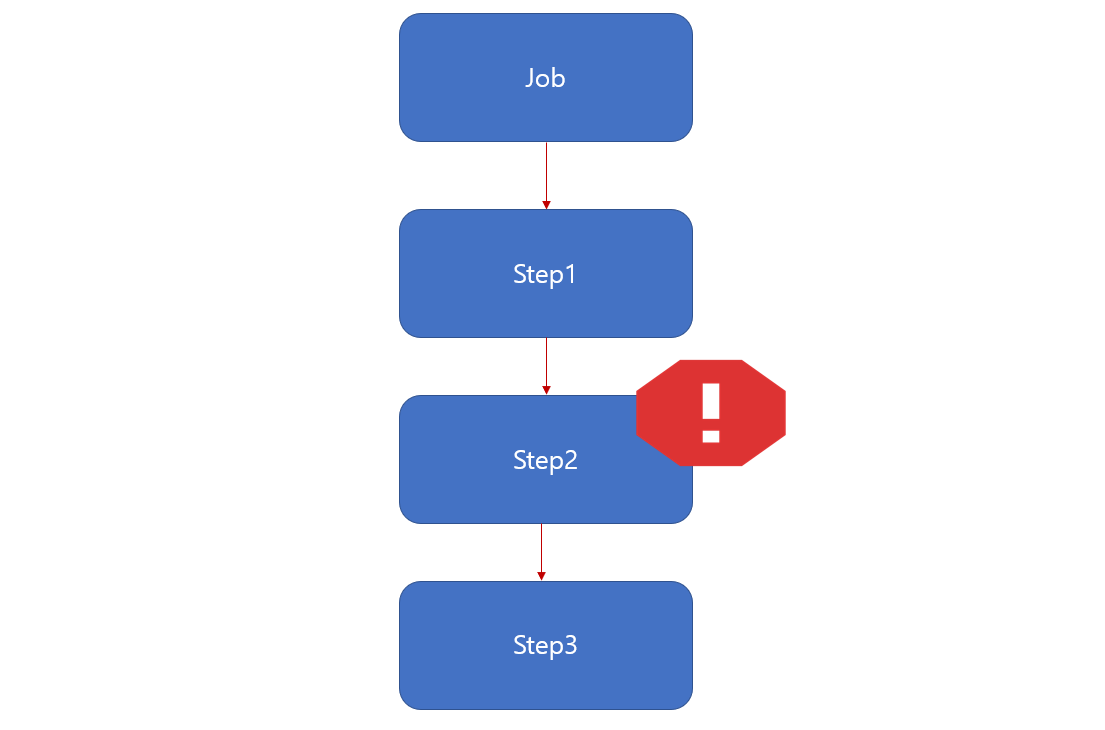
지금까지 우리는 배치 실행에 있어서 Job 이 있고 그 안에 Step 이 있다고 말씀드렸습니다.
예를들어 Job 안에 Step1, Step2, Step3 있다고 가정시 진행 도중 Step2 가 실패 했다면
해당 Job 은 실패로 됩니다. 물론 Step3 는 진행되지 않습니다.
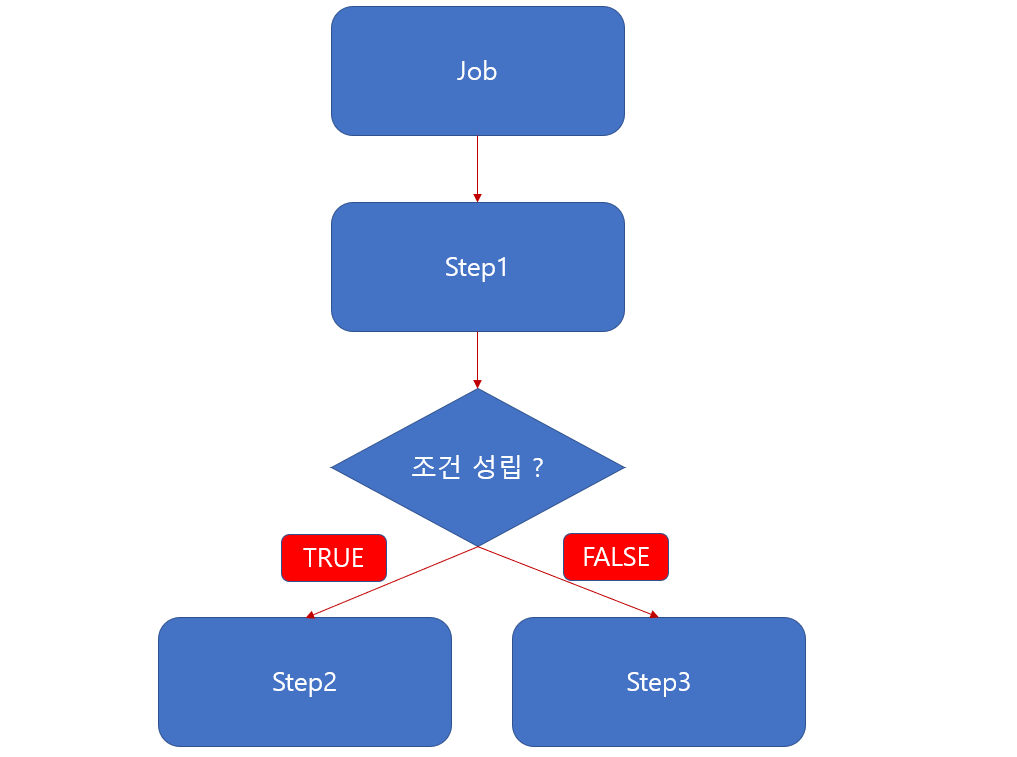
이제 우리가 배우는 Flow 경우 예를들어 Step1 에서 실패시 해당 Job 은 실패로 되는것이 아니라
Step3 로 진행하고 정상적으로 Step1 이 성공 했을때 Step2 로 진행 할 수 있습니다.
이렇게 분기에 따른 조건 성립을 구성 하고 싶을때 Flow 를 사용하게 됩니다.
FlowJob
본격적으로 FlowJob 에 대해서 알아보도록 하겠습니다. 간단한 예제를 준비 했습니다.
@RequiredArgsConstructor
@Configuration
public class BasicFlowConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job flowJob() {
return jobBuilderFactory.get("flowJob")
.start(flowStep1())
.on("COMPLETED").to(flowStep2())
.from(flowStep1())
.on("FAILED").to(flowStep3())
.end()
.build();
}
@Bean
public Step flowStep1() {
return stepBuilderFactory.get("flowStep1")
.tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("flowStep1");
if (true) {
throw new RuntimeException("TEST");
}
return RepeatStatus.FINISHED;
}
}).build();
}
@Bean
public Step flowStep2() {
return stepBuilderFactory.get("flowStep2")
.tasklet((contribution, chunkContext) -> {
System.out.println("flowStep2");
return RepeatStatus.FINISHED;
}).build();
}
@Bean
public Step flowStep3() {
return stepBuilderFactory.get("flowStep3")
.tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("flowStep3");
return RepeatStatus.FINISHED;
}
}).build();
}
}
‘flowJob’ 이라는 Job 을 만들어 보았습니다.
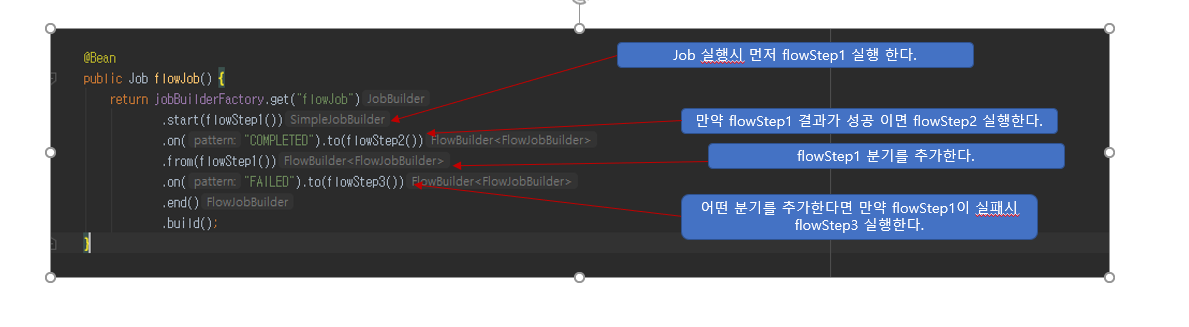
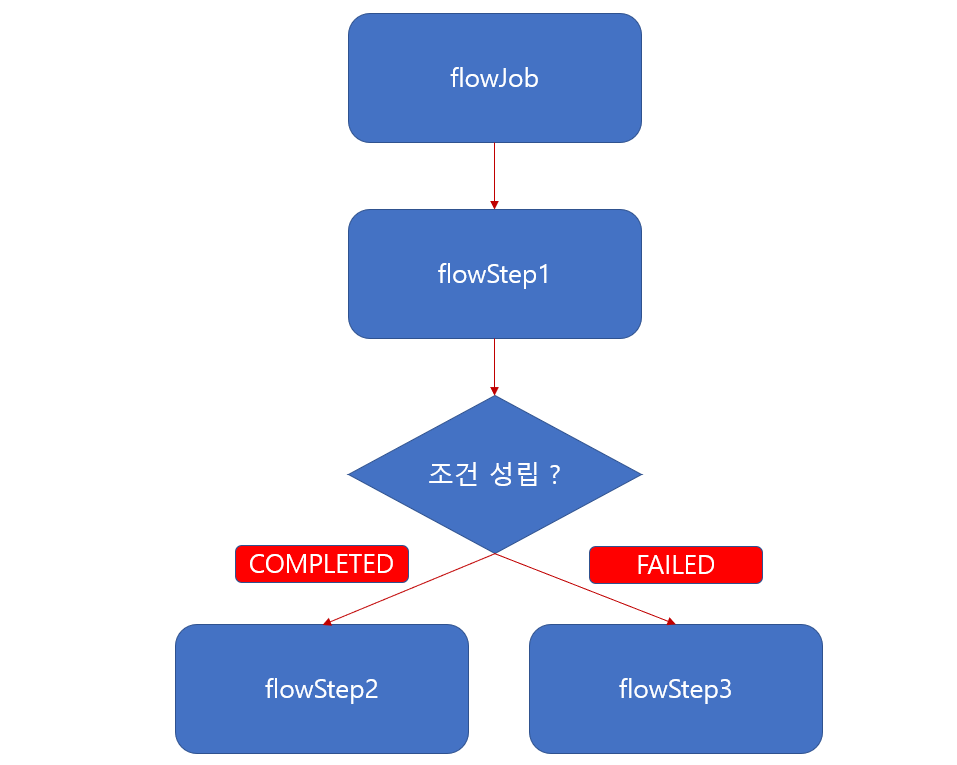
‘flowJob’ 이라는 이름을 가진 Job 이 실행되고 맨 처음 ‘flowStep1’ 이 실행 됩니다.
하지만 만약 실행 중 결과값이 ‘COMPLETED’ 이라면 ‘flowStep2’ 가 실행되고
‘FAILED’ 이라는 결과값이 나왔다면 ‘flowStep3’ 가 실행 하게 됩니다.
이제 한번 실행 해봅시다.
실행하기 앞써 이전에 ‘BasicJob’ 이라는 Job 을 만들었습니다.
실행하게 된다면 ‘BasicJob’ 도 실행하게 됩니다.
지정한 job 만 실행하고 싶을때는
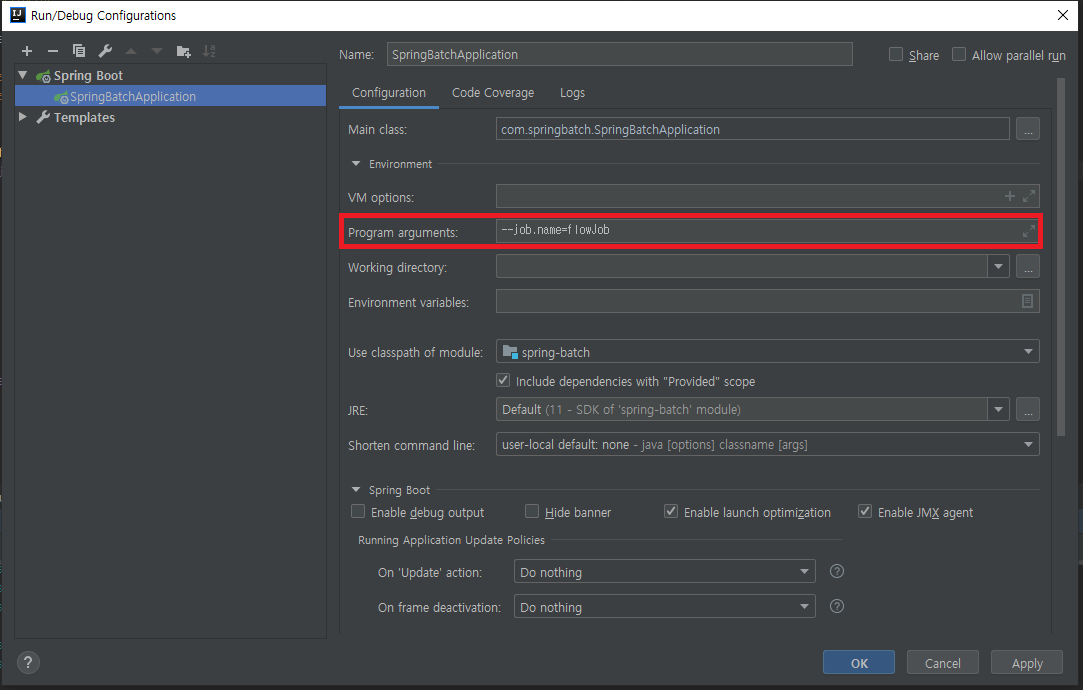
Configuration -> Program arguments 값을 지정 합시다.
--job.name=flowJob
마지막으로 application.yml 파일에 다음 내용을 추가 합니다.
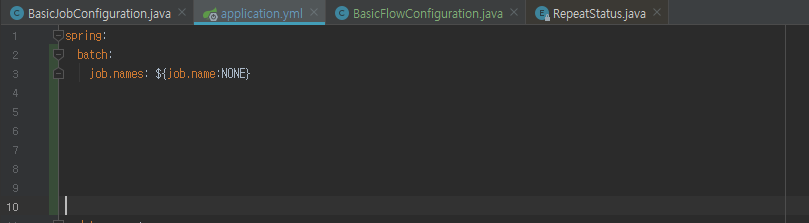
실행시 Program arguments ‘–job.name=flowJob’ 이라고 입력을 하게 된다면 ‘flowJob’ 이라는 job 만 실행하게 될 것 이고
만약 –job.name 값이 존재하지 않는다면 ‘NONE’ 으로 인식되어 아무 job 이든 실행 되지 않게 됩니다.
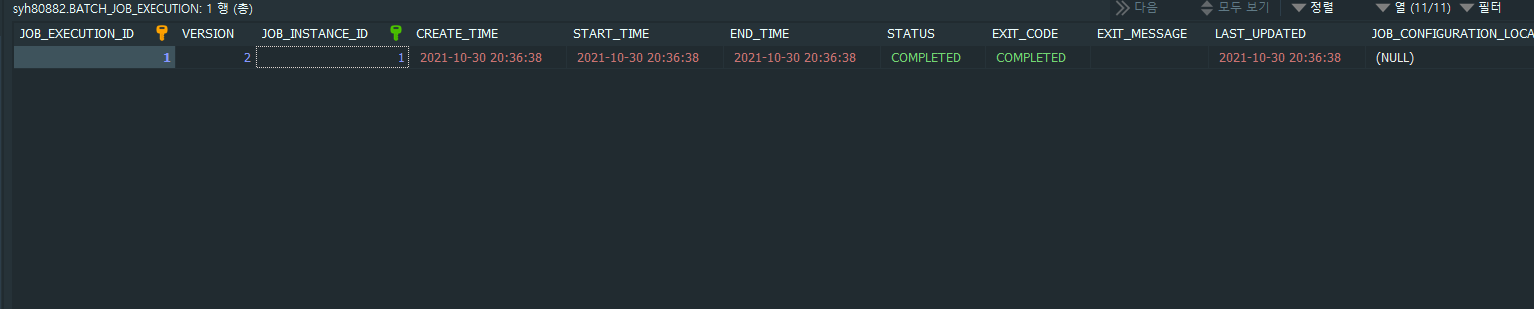
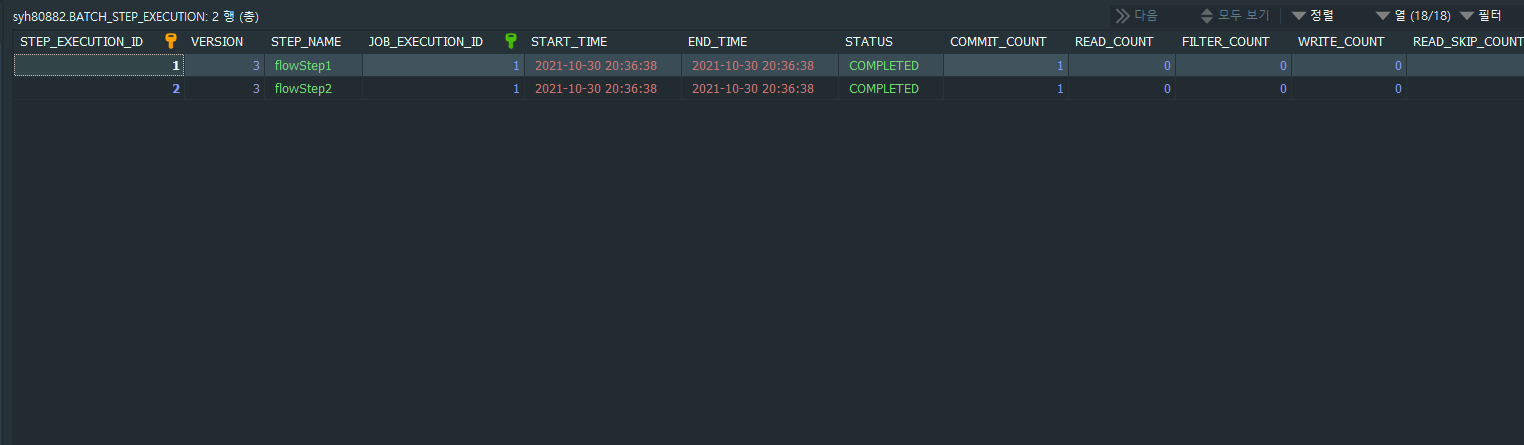
실행하면 Job ‘flowJob’, Step ‘flowStep1’, ‘flowStep2’ 정상적으로 성공 한것을 볼 수 있습니다.
‘flowStep1’ 성공하면 ‘flowStep2’ 정상적으로 실행 된다는 것을 확인 할 수 있었습니다.
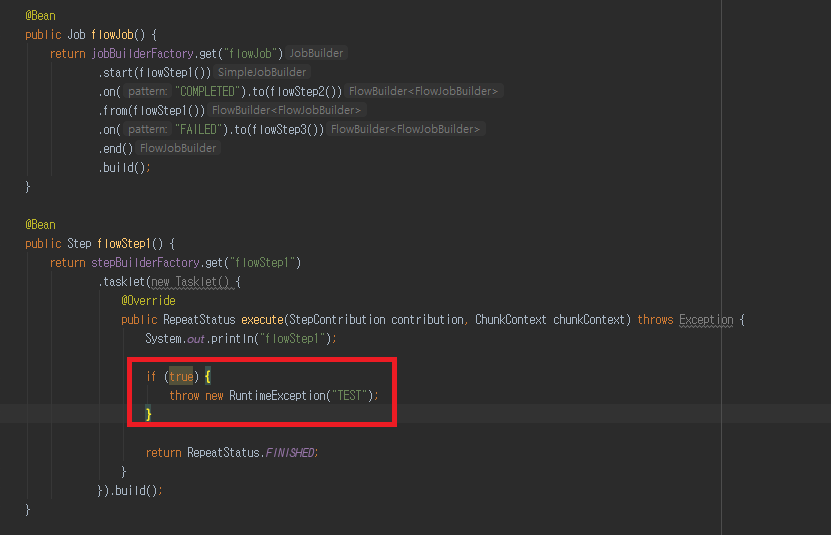
이번에는 flowStep1 에 일부러 Exception 을 발생 시키고 한번 실행 해봅시다.
다시 실행시에는 Spring Batch 메타데이터 초기화 후 진행 해주시길 바랍니다.
왜냐하면 같은 파라미터로 같은 Job 을 실행시 중복 실행으로 실행이 안되기 때문입니다.
번거롭지만 나중에는 파라미터를 자동 증가 설정 통해 관리가 가능하기 때문에 메타데이터 초기화 할 필요가 없습니다.
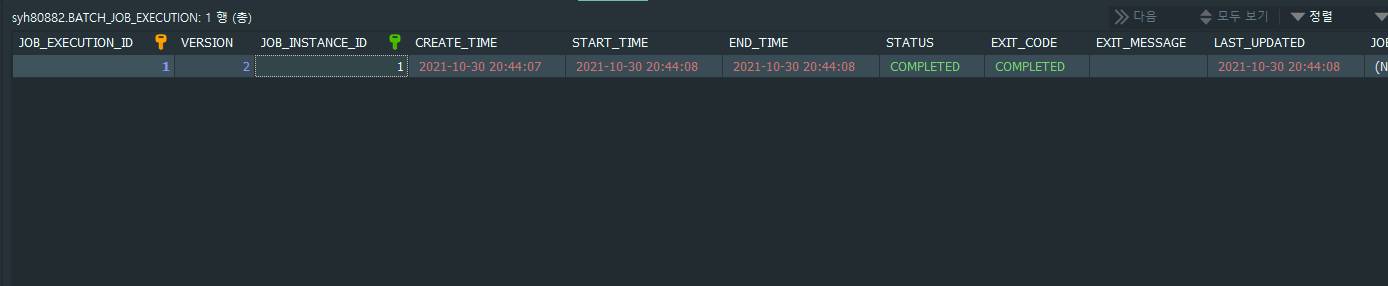

실행하면 Job ‘flowJob’
Step ‘flowStep1’ 실패 했습니다. 그래서 ‘flowStep3’ 으로 진행하게 되는데요. 여기서 특이할점은
기존 SimpleJob 경우에는 Step 이 실패하면 소속된 Job 도 실패하였지만 이번 FlowJob 경우에는 Step 이 실패해도 Job 은 성공 되었습니다.
FlowJob 의 특징인데요. 분기 처리를 지정했기 때문에 ‘flowStep1’ 에 실패해도 결국에는 ‘flowStep3’ 실행하라는 조건 설정을 지정했기에
전체적으로 보면 Job 은 실패가 아니게 됩니다.
더 복잡한 FlowJob 구성 해보자
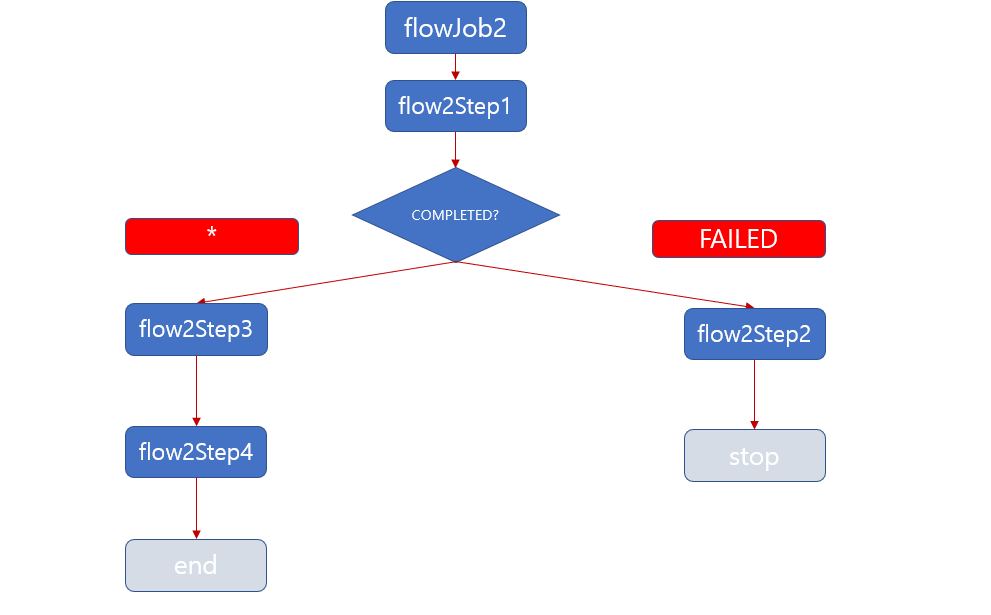
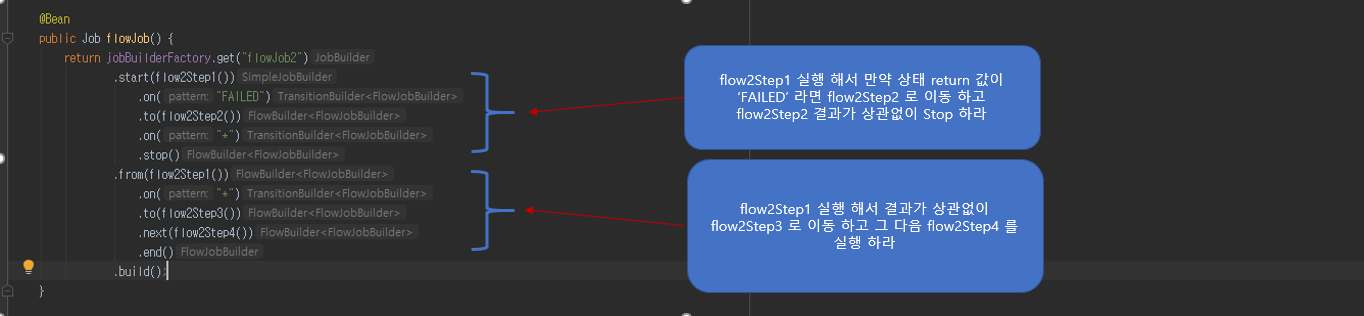
‘flowJob2’ 이라는 job 이 실행하면 바로 ‘flow2Step1’ 이 실행됩니다.
여기서 조건이 2가지로 분기 처리 됩니다. ‘flow2Step1’ ExitStatus 상태값이 ‘FAILED’ 값이라면 ‘flow2Step2’ 실행되고 이 후 ‘Stop’ 하게 됩니다.
그런데 만약에 ‘flow2Step1’ ExitStatus 상태값이 ‘FAILED’ 값 그외라면 (patten 이 *) ‘flow2Step3’ 실행되고 그 다음 ‘flow2Step4’ 실행 됩니다.
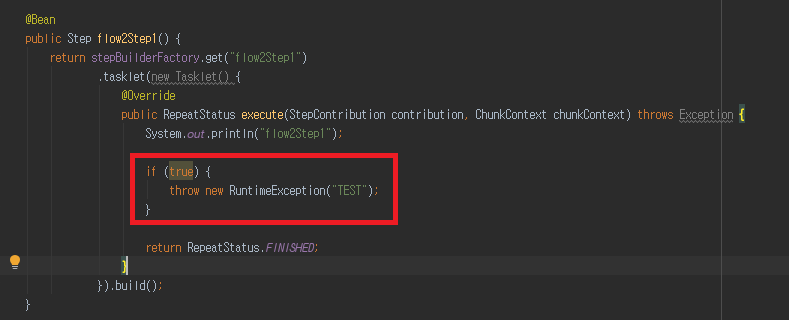
‘flow2Step1’ 비지니스 로직 안에 Exception 발생 하도록 하겠습니다.


BATCH_JOB_EXECUTION 테이블의 Job 상태값은 ‘STOPPED’ 되었습니다.
BATCH_STEP_EXECUTION 경우 flow2Step1 경우 ‘ABANDONED’ flow2Step2 는 ‘COMPLETED’ 되었습니다.
그럼 다시 ‘flow2Step1’ 비지니스 로직 안에 Exception 주석 처리 하고 Spring Batch 용 DB 를 모두 초기화 한 다음에 다시 실행 해보겠습니다.


‘flow2Step1’, ‘flow2Step3’, ‘flow2Step4’ 는 모두 ‘COMPLETED’ 로 되었습니다.
Spring Batch 에서 FlowJob 은 어떻게 실행할까?
프로젝트 기동
@Bean
public Job flowJob() {
return jobBuilderFactory.get("flowJob")
.start(flowStep1())
.on("COMPLETED").to(flowStep2())
.from(flowStep1())
.on("FAILED").to(flowStep3())
.end()
.build();
}
start 메소드
/**
* Create a new job builder that will execute a step or sequence of steps.
*
* @param step a step to execute
* @return a {@link SimpleJobBuilder}
*/
public SimpleJobBuilder start(Step step) {
return new SimpleJobBuilder(this).start(step);
}
on 메소드
SimpleJobBuilder.java
/**
* Branch into a flow conditional on the outcome of the current step.
*
* @param pattern a pattern for the exit status of the current step
* @return a builder for fluent chaining
*/
public FlowBuilder.TransitionBuilder<FlowJobBuilder> on(String pattern) {
Assert.state(steps.size() > 0, "You have to start a job with a step");
for (Step step : steps) {
if (builder == null) {
builder = new JobFlowBuilder(new FlowJobBuilder(this), step);
}
else {
builder.next(step);
}
}
return builder.on(pattern);
}
steps 변수에는 기존에 저장한 ‘flowStep1’ 한개가 저장 되어 있습니다. for 문을 돌면서 FlowJobBuilder 및 JobFlowBuilder 을 생성 합니다.
JobFlowBuilder 는 Flow 를 관리 및 제어 하는 역활을 합니다.
FlowJobBuilder 는 FlowJob 생성에 관여 합니다.
이후 builder.on(pattern) 을 하고 있습니다.
앞써 우리는 patten 을 “COMPLETE”, “FAILED” 로 입력 했었습니다. 이 pattern 에 지정함에 따라 Flow 흐름에 대한 분기처리 역활 담당한다고 보시면 되겠습니다.
FlowBuilder.java
public TransitionBuilder<Q> on(String pattern) {
return new TransitionBuilder<>(this, pattern);
}
on 메소드를 실행하게 되면 TransitionBuilder 생성 하게 됩니다. TransitionBuilder 는 앞서 설명한 pattern 에 지정함에 따른 Flow 흐름 제어 역활을 합니다.
end 메소드
FlowBuilder.java
public final Q end() {
return build();
}
JobFlowBuilder.java
@Override
public FlowJobBuilder build() {
Flow flow = flow();
if(flow instanceof InitializingBean) {
try {
((InitializingBean) flow).afterPropertiesSet();
}
catch (Exception e) {
throw new FlowBuilderException(e);
}
}
parent.flow(flow);
return parent;
}
FlowBuilder.java
protected Flow flow() {
if (!dirty) {
// optimization in case this method is called consecutively
return flow;
}
flow = new SimpleFlow(name);
// optimization for flows that only have one state that itself is a flow:
if (currentState instanceof FlowState && states.size() == 1) {
return ((FlowState) currentState).getFlows().iterator().next();
}
addDanglingEndStates();
flow.setStateTransitions(transitions);
flow.setStateTransitionComparator(new DefaultStateTransitionComparator());
dirty = false;
return flow;
}
이후에 배우게 되는 SimpleFlow 생성 합니다.
FlowJobBuilder.java
protected FlowJobBuilder flow(Flow flow) {
this.flow = flow;
return this;
}
생성한 SimpleFlow 객체를 FlowJobBuilder 클래스인 flow 변수에 담습니다.
build 메소드
FlowJobBuilder.java
/**
* Build a job that executes the flow provided, normally composed of other steps.
*
* @return a flow job
*/
public Job build() {
FlowJob job = new FlowJob();
job.setName(getName());
job.setFlow(flow);
super.enhance(job);
try {
job.afterPropertiesSet();
}
catch (Exception e) {
throw new StepBuilderException(e);
}
return job;
}
SimpleFlow 객체를 생성했던 flow 변수 담았던 것과 Job 이름와 함께 최종적으로 FlowJob 생성 합니다.
배치 실행
FlowJob.java
/**
* @see AbstractJob#doExecute(JobExecution)
*/
@Override
protected void doExecute(final JobExecution execution) throws JobExecutionException {
try {
JobFlowExecutor executor = new JobFlowExecutor(getJobRepository(),
new SimpleStepHandler(getJobRepository()), execution);
executor.updateJobExecutionStatus(flow.start(executor).getStatus());
}
catch (FlowExecutionException e) {
if (e.getCause() instanceof JobExecutionException) {
throw (JobExecutionException) e.getCause();
}
throw new JobExecutionException("Flow execution ended unexpectedly", e);
}
}
생성한 FlowJob 에서 SimpleFlow 객체를 담았던 flow 변수를 차례대로 실행하게 됩니다.
결국 FlowJob 는 초기 기동시 담았던 SimpleFlow 실행하는 구조 입니다.
SimpleFlow
SimpleFlow 에 대해 알아보도록 하겠습니다. 부모 클래스인 Flow 구현체 입니다. Flow 에서는 State 라는 값이 있는데
Flow, Step, JobExecutionDecider 같은 객체를 담아서 배치 실행시 담아 있는 객체를 실행하는 역활을 합니다.
결국은 Flow 안에 Step, Flow 같은 객체를 품고 품고 있던 객체를 실행하는 구조 입니다.
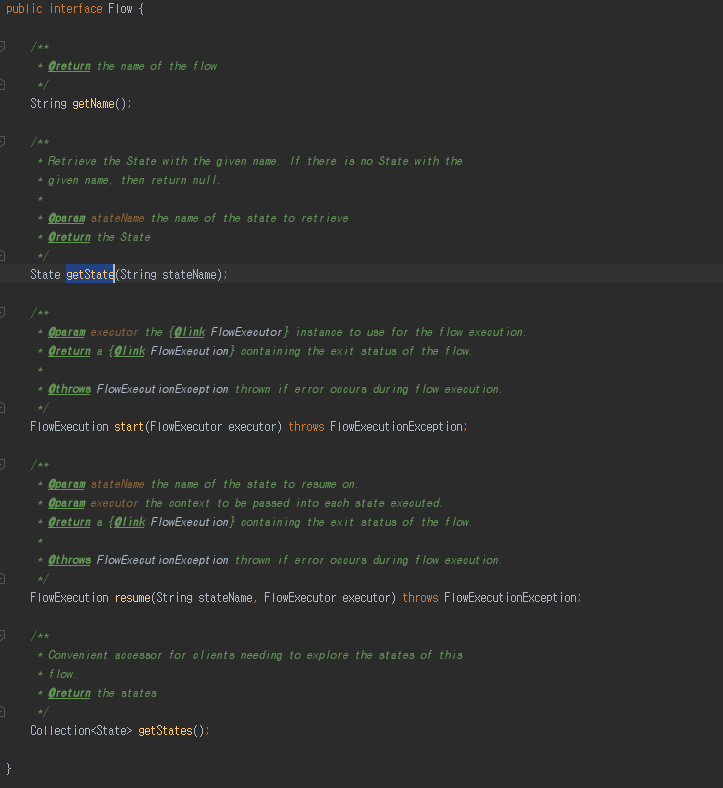
SimpleFlow 부모인 Flow 입니다.
- getName(): Flow 이름 가져올때 사용 됩니다.
- getState(): state 안에는 Flow, Step, JobExecutionDecider 같은 객체가 담아져 있는데 해당 state 이름을 가져올때 사용 됩니다.
- start(): Flow 실행하는 메소드 입니다.
- resume(): 다음 Flow 를 실행하는 state 구해서 FlowExecutor 위임 할때 사용 합니다.
- getStates(): 해당 Flow 가 가지고 있는 모든 state 를 가져올때 사용 됩니다.
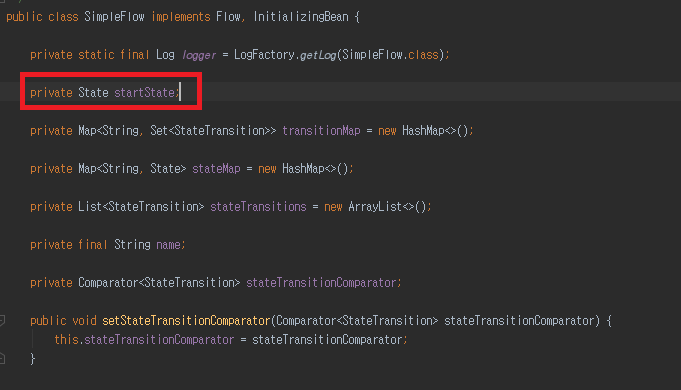
SimpleFlow 클래스 입니다. 중요하게 봐야 하는 부분은 State 객체가 선언 되어 있다는 것 입니다.
State 객체를 한번 볼까요?
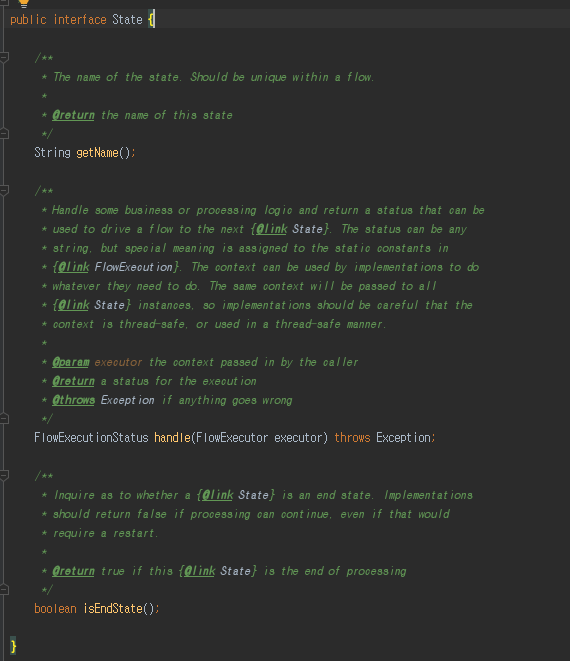
state 클래스에서 handle 메소드 경우 해당 구현체를 실행 하는 역활을 합니다.
예를들어 FlowState 객체를 handle 메소드를 실행하면 Flow 객체를 실행 하게 됩니다.
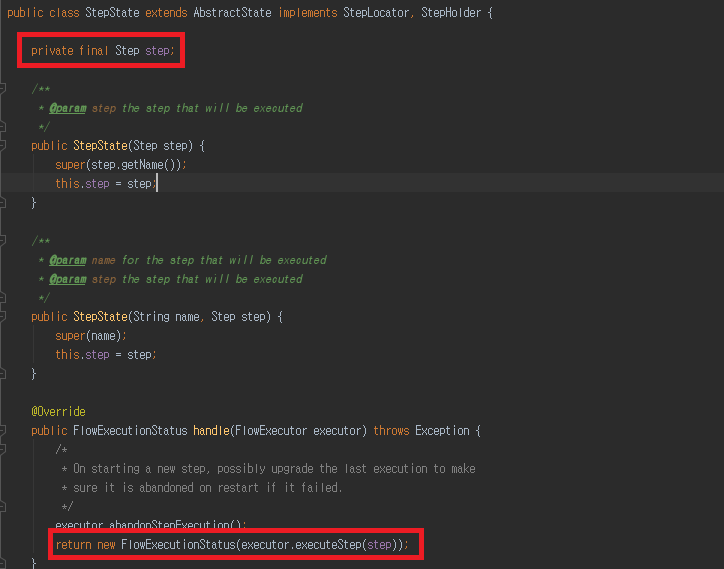
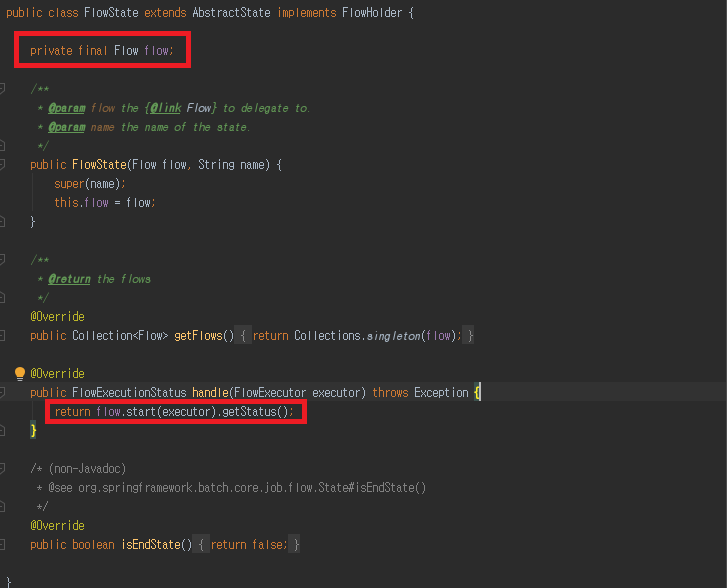
이렇게 State 객체 구현체는 StepState, FlowState 등 있습니다. 이러한 객체는 각각의 Step, Flow 객체가 선언 되어 있습니다.
배치 실행시 이러한 해당되는 객체를 저장했다가 handle 메소드 통해 실행 되는 구조 라고 보면 되겠습니다.
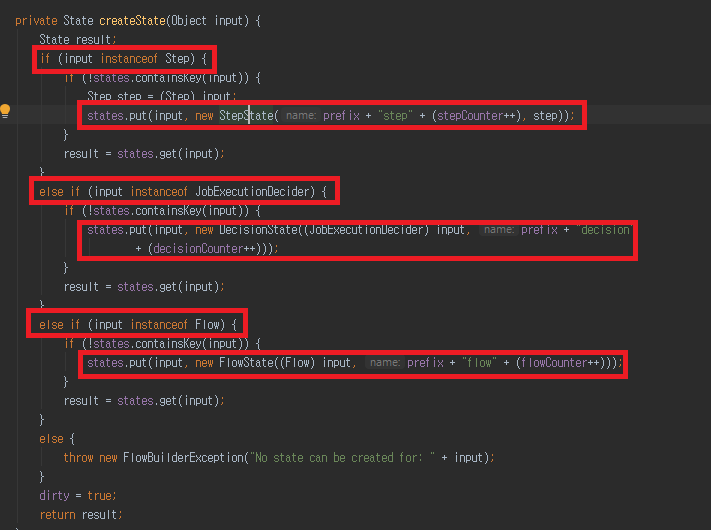
FlowBuilder.java -> createState 메소드 입니다. 해당 메소드 실행 시점은 Running 시점 입니다. 즉 프로세스가 올라갈때 입니다.
Object 객체를 전달 받아 (결국은 Step, JobExecutionDecider, Flow 객체 중 하나 입니다.) 해당 객체를 state 객체에 담고 있는것을 확인 할 수 있습니다.
state 담았던 객체를 나중에 각각 실행 한다고 보면 되겠습니다.
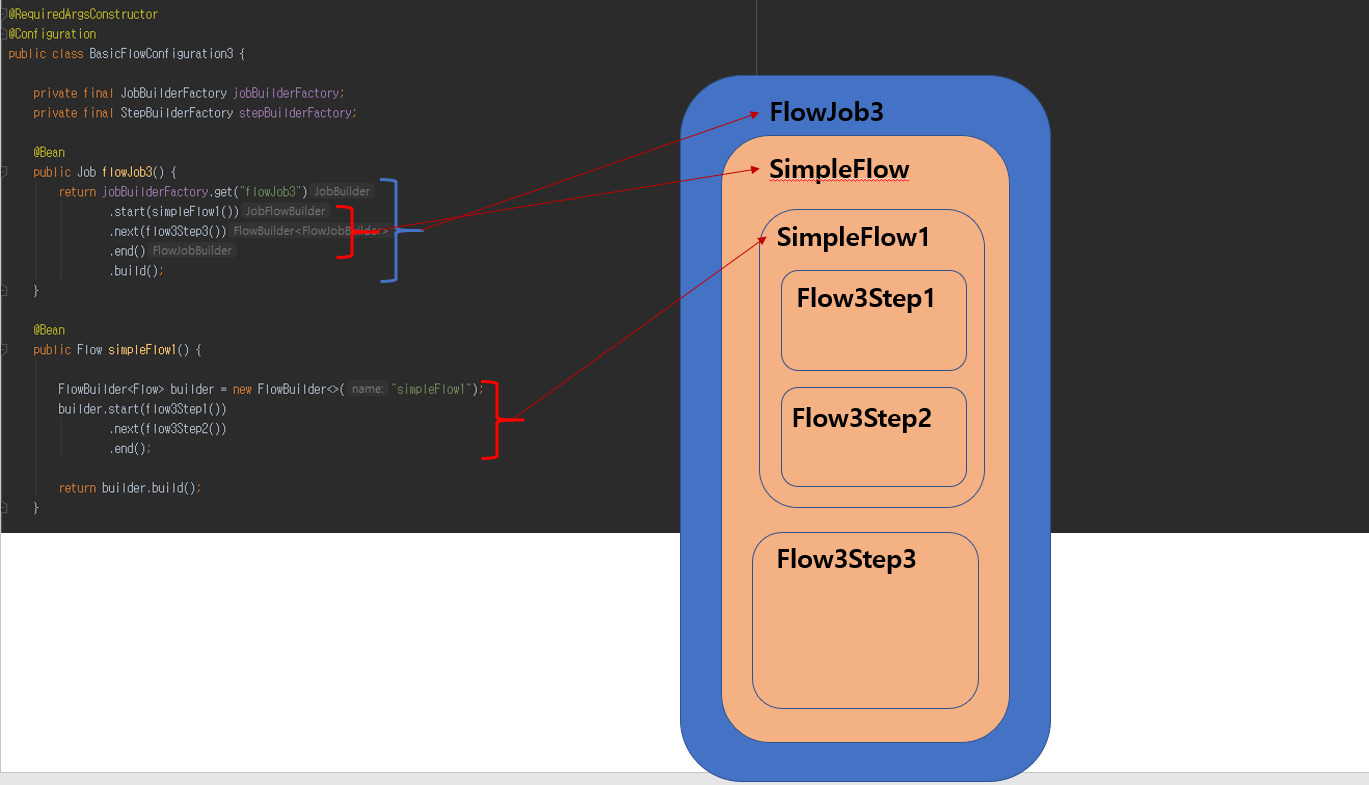
그럼 예제를 통해 설명하도록 하겠습니다.
FlowJob3 가 그 안에 SimpleFlow, Flow3Step3 를 포함 한다고 보면 되겠습니다.
SimpleFlow 안에 SimpleFlow1 이 있고 SimpleFlow1 안에는 Flow3Step1, Flow3Step2 가 포함 되고 있다고 보시면 되겠습니다.
각각의 객체가 state 값에 따라 Flow 객체면 Flow 를 실행하고 Step 객체면 Step 이 실행 됩니다.