
Spring Batch
예제 소스 코드
이번 블로그에 사용되는 코드는 아래 링크 통해 확인 할 수 있습니다.
https://github.com/syh8088/spring-batch
이번 시간은 Spring Batch 에 대해서 알아보는 시간을 갖도록 하겠습니다.
대부분 서비스 업체라면 일정 시간대에 Scheduler 통해 Batch 를 실행 해 대량의 데이터를 일괄 처리하는 시스템이 있습니다.
예를들어 매일 00:00 에 닥톡 서비스 내 모든 병원 각각의 메세지 발송 건수를 가져와서 건수에 따른 발송 비용을 계산해 정산 테이블 Insert 하는 일괄 처리가 있다고 가정 해봅시다.
일단 모든 병원을 조회하고 처리하는 과정에서 많은 부하가 일어납니다. 그래서 부하가 적은 새벽 시간대에 정해서 일괄 처리를 하는 것 입니다.
즉 비효율적인 서버 과부하를 줄이기 위해서 입니다.
Spring 진영에서는 이러한 일괄 처리를 할 수 있도록 도와주고 프레임워크를 만들어 표준화 한 것이 Spring Batch 입니다.
자세히 말하자면 일괄처리 전문적으로 관리 및 처리 할 수 있도록 Pivotal 사와 Accenture 사(일괄처리 프레임워크 기술 가지고 있는 회사) 협력해서 탄생한 것이 Spring Batch 입니다.
사실 Spring Batch 탄생 전에 대부분 서비스 업체에서는 자체 사내 솔루션을 개발하는 경우가 많았습니다.
그만큼 유지보수 관리 측면에서 어려움이 있고 일괄 처리 외에 배치 시스템 구축에 따른 시간 및 비용 소모
일괄 처리에 대한 비지니스 로직에 집중만 할 수 없었던 단점이 있었습니다.
- 일괄처리를 위한 배치 프로세스 실행 및 처리
- 배치 실패 된다면 실패 예외 처리 및 후속 처리 지원 (재실행 가능)
- 대용량 일괄 처리를 위한 멀티 스레드 지원
- Job(1) - Step(N) 에 상호작용 통한 철저한 단계 통해 배치 실행
- 조건에 따른 각각의 일괄처리에 따른 다시 실행 및 실행하지 않고 다음 단계로 넘어 갈수 있는 Flow 제공
- 일괄처리 전용 TEST 코드 제공
이렇게 Spring Batch 에서는 여러가지 기능을 제공 합니다.
덕분에 우리는 오로지 일괄처리를 위한 비지니스에 집중 할 수 있습니다.
예시로
닥톡 이용하고 있는 모든 각각 병원들이 SMS 발송 건수를 구하고 건수에 따른 일일 비용을 계산해서 정산 테이블에 INSERT 한다. 그리고 각각의 병원들의 비용을 해당 병원에게 이메일로 전달 한다.
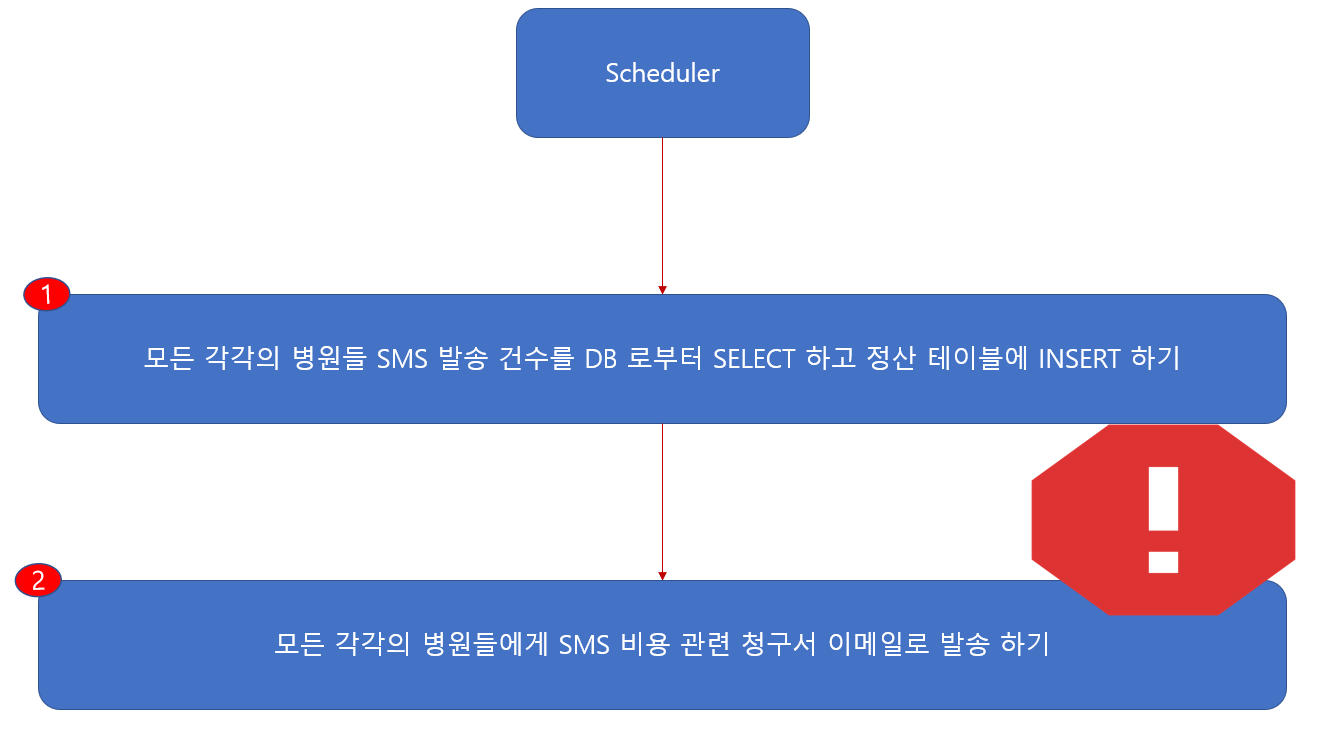
이렇게 일괄 처리를 하게 된다고 하면
1번 ‘모든 각각의 병원들 SMS 발송 건수를 DB 로부터 SELECT 하고 정산 테이블에 INSERT 하기’ 처리를 마치고
2번 ‘모든 각각의 병원들에게 SMS 비용 관련 청구서 이메일로 발송 하기’ 여기서 로직 수행 중 에러가 발생 되었다고 가정 해봅시다.
그럼 개발자는 2번 내용의 비지니스 로직 에러를 수정을 해야 하고 다시 해당 일괄 처리를 해야 합니다.
그러나 여기서 1번은 처리를 완료되었고 2번 처리를 해야 하는 상황에 그에 따른 로직도 변경 작업이 필요로 합니다.
Spring Batch 에서는 이러한 불편함을 해소하기 위해 해당 일괄 처리 배치를 다시 실행 된다면
1번 작업은 건너뛰고 2번 작업으로 들어갈수 있도록 도와줍니다. 특별한 로직 수정 필요없이 입니다.
그리고 해당 일괄 처리는 무조건 하루에 한번 실행 해야 하는 상황일때
실수로 개발자가 오류 내용 수정 후 해당 일괄 처리를 2번 실행 하는 실수를 방지 해줍니다.
그럼 지금부터 Spring Batch 에 대해 자세히 알아보겠습니다.
Spring Batch 프로젝트 구성
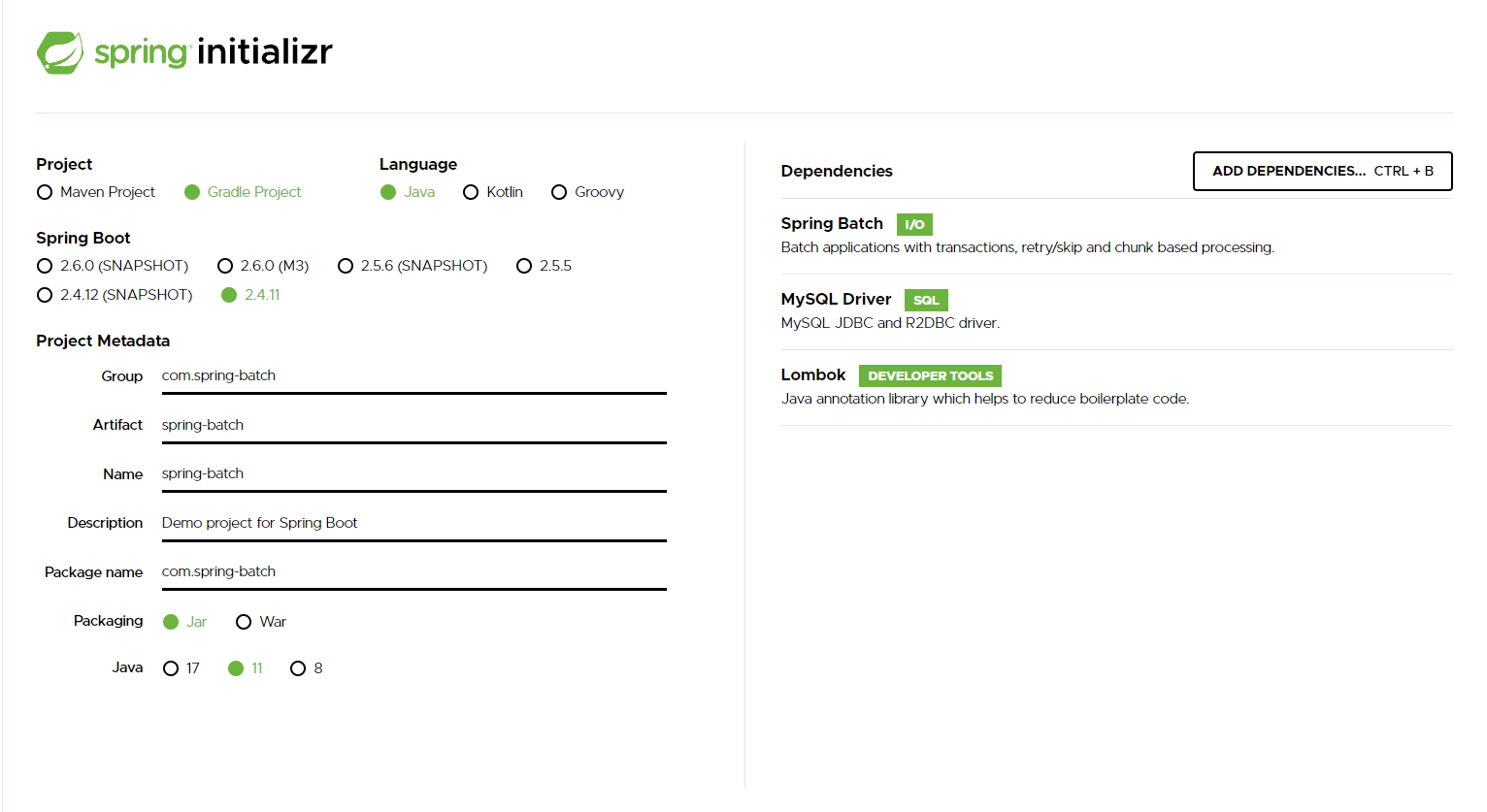
프로젝트 구성을 위 이미지로 출발 하겠습니다.
먼저 Spring Batch 가 필요 합니다. 그리고 mysql-connector-java 있습니다. 나중에 Spring Batch 통해 일괄처리시 각각의 실행 관련 메타 데이터를 저장 하는 용도로
DB 가 필요합니다.
mysql 아니더라도 h2, oracle 등 가능 합니다.
- Java 11
- Spring Boot 2.4.11
- Gradle
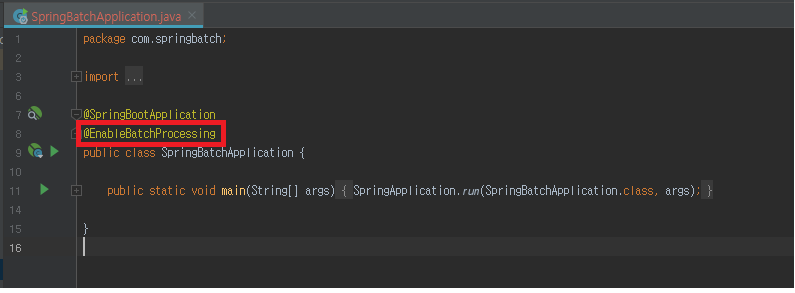
@EnableBatchProcessing
Spring 프로젝트 main 메소드에 @EnableBatchProcessing 어노테이션을 추가 합니다.
그럼 기본적인 Spring Batch 지원하는 기능들을 활성화 및 사용 할 수 있도록 해줍니다.
Spring Batch 계층 구조
Spring Batch ‘Job’ ‘Step’ ‘Tasklet’ 알아보기
Spring Batch 에서 가장 기본적인 ‘Job’ ‘Step’ ‘Tasklet’ 각각 알아보도록 하겠습니다.
우선 설명전 예시로
닥톡 이용하고 있는 모든 각각 병원들이 SMS 발송 건수를 구하고 건수에 따른 일일 비용을 계산해서 정산 테이블에 INSERT 한다. 그리고 각각의 병원들의 비용을 해당 병원에게 이메일로 전달 한다.
해당 건을 처리 해야 한다고 했을때
여기서 우리는 크게 비니지스 로직이 2가지를 처리해야 합니다.
- 모든 각각의 병원들 SMS 발송 건수를 DB 로부터 SELECT 하고 정산 테이블에 INSERT 하기
- 모든 각각의 병원들에게 SMS 비용 관련 청구서 이메일로 발송 하기

이렇게 2가지를 처리 한다고 했을때
Spring Batch 의 ‘Job’ 은 하나의 큰 개념의 작업 단위 즉 예시로 기재했던 것이 하나의 Job 으로 생각 하시면 됩니다.
그 다음으로 Spring Batch 의 ‘Step’ 은 바로 위에 2가지 기재 했던 각각의 작업 수행 단위 입니다.
마지막으로 ‘Tasklet’ 는 이러한 각각의 비지니스 로직을 수행하고 처리하는 역활 이라고 보시면 되겠습니다.
하나의 Job 은 적어도 한개 이상의 Step 이 반드시 필요 합니다.
간단한 Spring Batch 실행 해보기
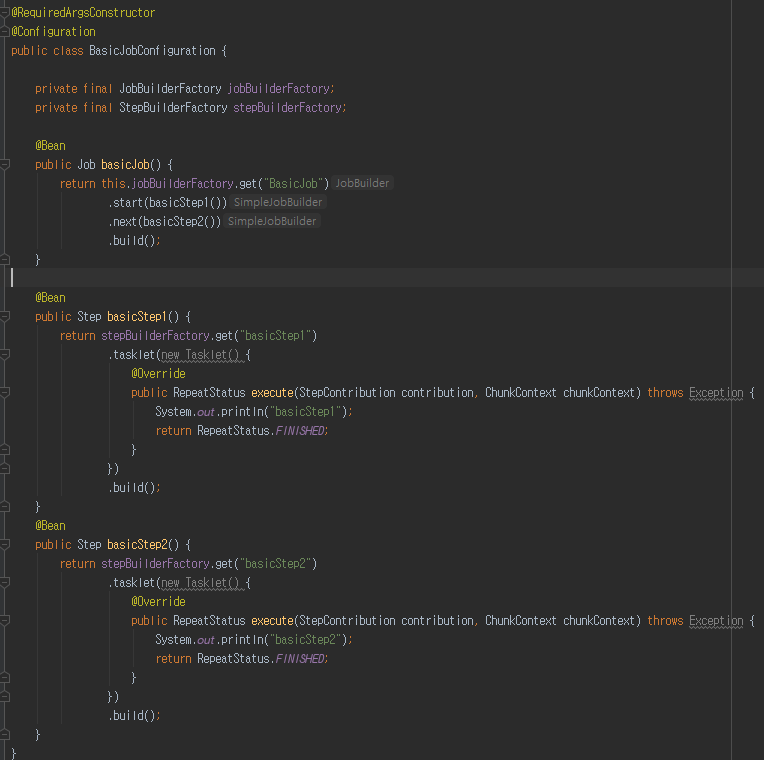
여기까지 Job, Step, Tasklet 는 간단히 설명했으니 대강 감이 오실것 같습니다.
하나하나 자세한 설명은 이후 진행될 예정이니 지금은 간단하게 Spring Batch 실행 한다는 관점에서 해볼려고 합니다.
JobBuilderFactory 클래스가 ‘Job’ 을 생성하고
StepBuilderFactory 클래스가 ‘Step’ 을 생성 하는것을 볼수 있습니다.
생성한 Step 은 생성한 Job ‘start’, ‘next’ 통해 전달 하고 있습니다.
Tasklet 는 각각 생성한 Step 에서 생성 된것을 볼 수 있습니다.
여기 안에 일괄 배치 할 비지니스 로직이 수행 한다고 보면 되겠습니다.
RepeatStatus.FINISHED;
Tasklet 실행 후 특별한 경우 제외한다면 무한 반복을 방지 해야 하기 때문에 상태값을 FINISHED 로 반환 합니다.
즉 실행하면 Job -> Step1 -> Step2 가 진행 한다고 보면 되겠습니다.
이제 다음으로는 Spring Batch 의 메타데이터 관리 및 보관하는 스키마를 데이터베이스에 등록해야 합니다.
우리는 데이터베이스를 mysql 를 사용하고 있으니 mysql 전용 스키마로 등록 해야합니다.
물론 h2, 오라클 등 그외 스키마도 Spring Batch 에서 제공 하고 있습니다.
schema-mysql.sql
해당 파일을 검색 해봅시다.
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
해당 쿼리문을 실행해서 등록 합니다.
참고로 여기서 말하는 메타데이터는 Spring Batch 에서 배치를 실행 한다고 예를 들자면
배치 실행에 있어 히스토리 기록 및 각각의 Job, Step 등 실행 및 결과 상태값 기록 관리 하게 됩니다.
하나하나 테이블 설명은 이후 자세하게 설명 할 예정입니다.
쿼리 실행 후 프로세스를 실행 해봅시다.
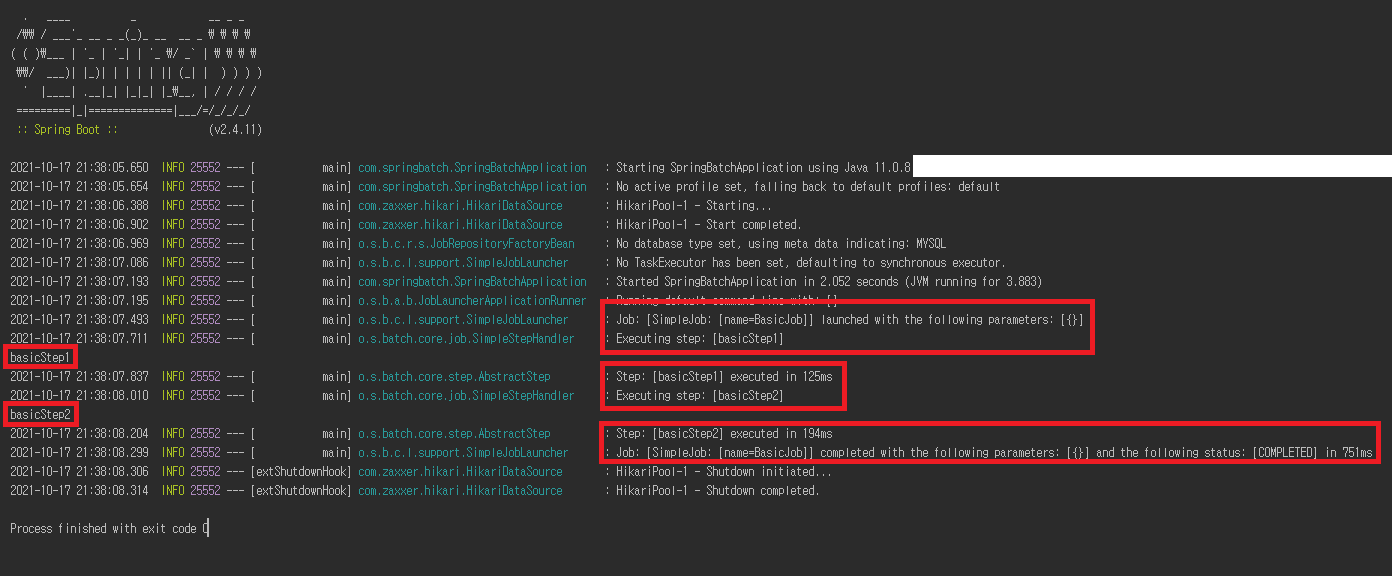
Job: [SimpleJob: [name=BasicJob]] launched with the following parameters: [{}]
Job 을 실행 로그 내용입니다. 여기서 SimpleJob 보이는데 최상위 인터페이스인 Job 구현체인 SimpleJob 입니다.
SimpleJob 은 나중에 Job Part 에서 자세히 설명하겠지만 Spring Batch 에서 지원하는 Default 인 Step 을 순차적으로 실행 목적으로 만든 Job 입니다.
해당 SimpleJob 은 ‘BasicJob’ 이라는 이름으로 실행되고 ‘[{}]’(빈값) 이라는 파라미터 값으로 실행 되었다는것을 볼 수 있습니다.
이것도 나중에 자세히 설명하겠지만 Spring Batch 에서는 해당 Job(우리가 ‘BasicJob’ 지정한 Job 이름) 을 실행 후 다시 실행을 막기 위해
파라미터 값을 통해 해당 Job 을 실행 할지 안할지 판단합니다.
파라미터 값이 빈값 통해 실행 했으니 다시 실행하면 에러가 발생됩니다.
다시 Job 을 실행 할려면 파라미터 값을 이전 과거에 입력했던 값과 다르게 설정 해야 합니다.
Executing step: [basicStep1]
Executing step: [basicStep2]
이제 해당 Job 에 포함된 Step 2개가 실행 되었다는 것을 볼수 있습니다.