
안녕하세요. 닥프렌즈 서버개발자🐥 최다영입니다. 저는 최근에 여러명의 목소리로 녹음된 음성을 텍스트로 변환해 채팅처럼 보여주는 서비스 개발에 참여했습니다. 현재 저희 팀에는 따로 프론트엔드 개발자가 없기 때문에 프론트엔드부터 백엔드까지 전반적인 내용을 개발하게 되었는데요. 이 글에서는 어떤 구조로 오디오를 텍스트로 변환했는지, 변환된 텍스트를 어떻게 채팅 형식으로 보여주었는지에 대해 공유하려고 합니다. (녹음된 오디오를 여러 채널로 분리하는 내용은 이 글에서는 다루지 않습니다)
서버 구조와 처리 순서
녹음된 오디오를 텍스트로 제공하는 서비스는 총 3개의 닥톡 서버와 네이버 CLOVA API 서버가 사용됩니다.
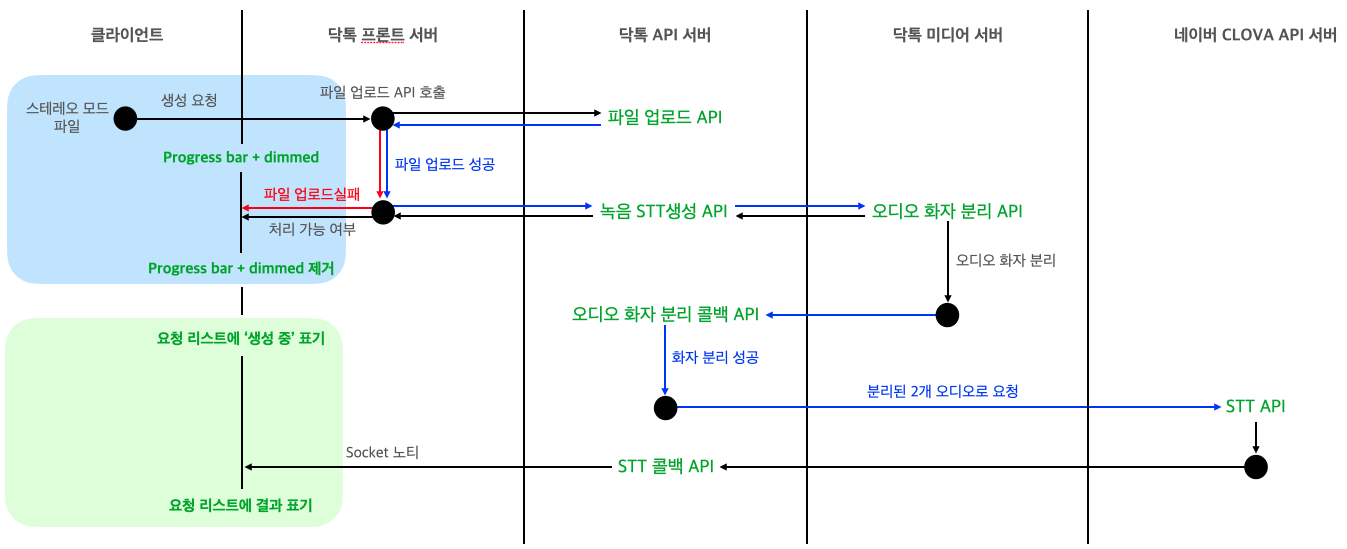
위 구조에서 특징적인 부분은 클라이언트가 스테레오 모드로 녹음된 파일을 업로드 한다는 점과 미디어 서버의 역할인데요. 미디어 서버는 클라이언트가 업로드한 녹음 파일을 두 개의 채널로 분리하는 요청을 처리합니다.
예를 들어, 두 화자의 목소리로 녹음된 내용이 아래와 같을 때,
화자 A : 반갑습니다. 저는 닥톡 담당자입니다.
화자 B : 안녕하세요. 닥톡 서비스는 언제 사용하면 좋은 서비스인가요?
화자 A : 닥톡은 환자와 의사를 이어주는 주치의 메신저 플랫폼 서비스입니다. 언제든 실시간으로 병원 예약 접수를 할 수 있고, 대기자 현황까지 확인이 가능합니다. 또한 자신의 목소리 모델을 화자 이용하여 건강상담 동영상을 만들어 네이버 지식iN과 유튜브에 자동 검색노출시키는 동영상 제작, 배포도 제공한답니다.
화자 B : 네. 한번 써봐야겠네요.
화자 A : 좋아요. 이용 중 문의사항은 닥톡 홈페이지 고객센터 문의 또는 서비스 운영팀의 단톡방으로 문의해 주세요.
미디어 서버에서는 음성의 데시벨에 따른 계산, 잡음처리 등을 거쳐 업로드된 녹음 파일과 동일한 재생시간을 갖는 두 개의 오디오 파일(한 파일에는 한 화자의 음성만 포함된)을 생성합니다. 분리된 파일의 내용은 아래와 같습니다.
화자 A : 반갑습니다. 저는 닥톡 담당자입니다.
화자 A : 닥톡은 환자와 의사를 이어주는 주치의 메신저 플랫폼 서비스입니다. 언제든 실시간으로 병원 예약 접수를 할 수 있고, 대기자 현황까지 확인이 가능합니다. 또한 자신의 목소리 모델을 이용하여 건강상담 동영상을 만들어 네이버 지식iN과 유튜브에 자동 검색노출시키는 동영상 제작, 배포도 제공한답니다.
화자 A : 좋아요. 이용 중 문의사항은 닥톡 홈페이지 고객센터 문의 또는 서비스 운영팀의 단톡방으로 문의해 주세요.
화자 B : 안녕하세요. 닥톡 서비스는 언제 사용하면 좋은 서비스인가요?
화자 B : 네. 한번 써봐야겠네요.
이렇게 나눠진 두 파일을 각각 네이버 CLOVA API로 보내면, 각 음성을 문장 or 단어 단위로 나눠 텍스트로 변환한 결과를 받게 됩니다. 변환 결과로 받은 데이터는 {오디오 시작 시간, 오디오 종료 시간, 텍스트, ...}와 같이 구성되어 있는데요. 저희는 하나의 {오디오 시작 시간, 오디오 종료 시간, 텍스트, ...} 묶음 단위를 segment라고 칭하고 있습니다. 프론트 서버에서는 이 결과 segment 리스트로 마치 두 화자가 텍스트로 채팅을 한 듯 표현을 할 수 있는 것입니다.
프론트엔드
아래 이미지는 클라이언트가 업로드한 녹음 파일을 네이버 CLOVA API까지 요청 후 모두 성공 처리되었을 때, 클라이언트에게 제공되는 상세 페이지입니다.
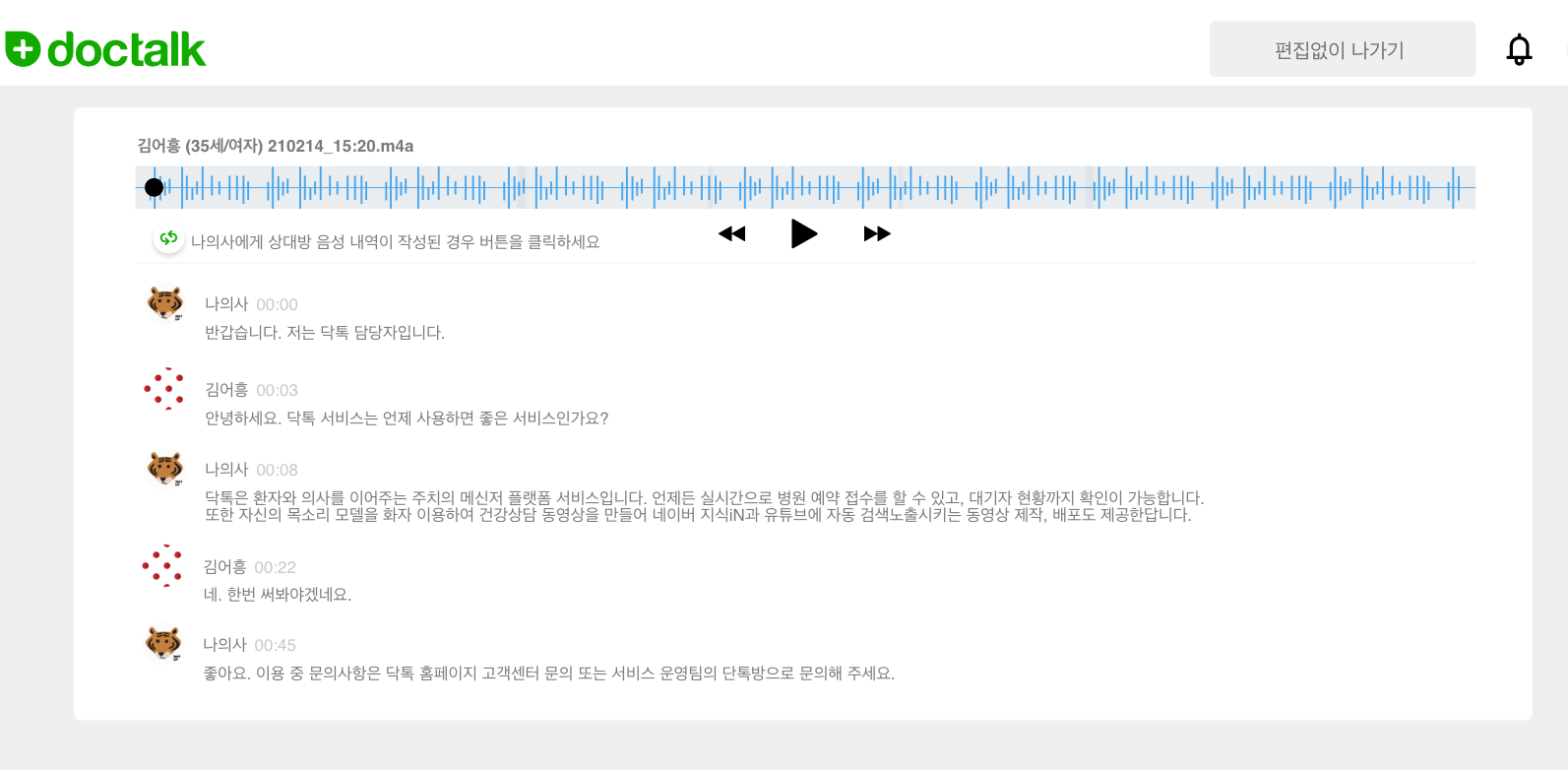
상세 페이지에서 제공되는 기능
- 화자별 텍스트 출력
- 화자 변경
- 텍스트 수정
- 선택한 텍스트 영역에 해당하는 오디오 재생
- 선택한 오디오 영역에 해당하는 텍스트 영역 포커싱 + 오디오 재생
상세 페이지를 개발하며 가장 어려웠던 부분은 위 기능 중 4번과 5번에 해당하는, 오디오와 텍스트의 싱크를 맞추는 부분이었습니다. 즉, 오디오 wave 영역과 재생/일시정지 버튼, 재생되는 텍스트 영역까지 모두 동일한 패턴으로 동작하도록 해야되는 문제인데요. “하나의 메서드는 하나의 기능만 수행한다”를 여러번 되뇌이며🔥 작은 단위로 나누며 개발하다 보니 다행히 잘 해결할 수 있었습니다.
그래서 프론트엔드 부분에서는 위에서 언급했던 segment에 초점을 맞춰 어떻게 화자별 텍스트를 채팅 형식으로 출력했는지만 공유하도록 하겠습니다.
화자별 텍스트 출력
두 오디오에 대한 STT API 결과는 데이터베이스에 각 오디오별로 나뉘어 저장됩니다.
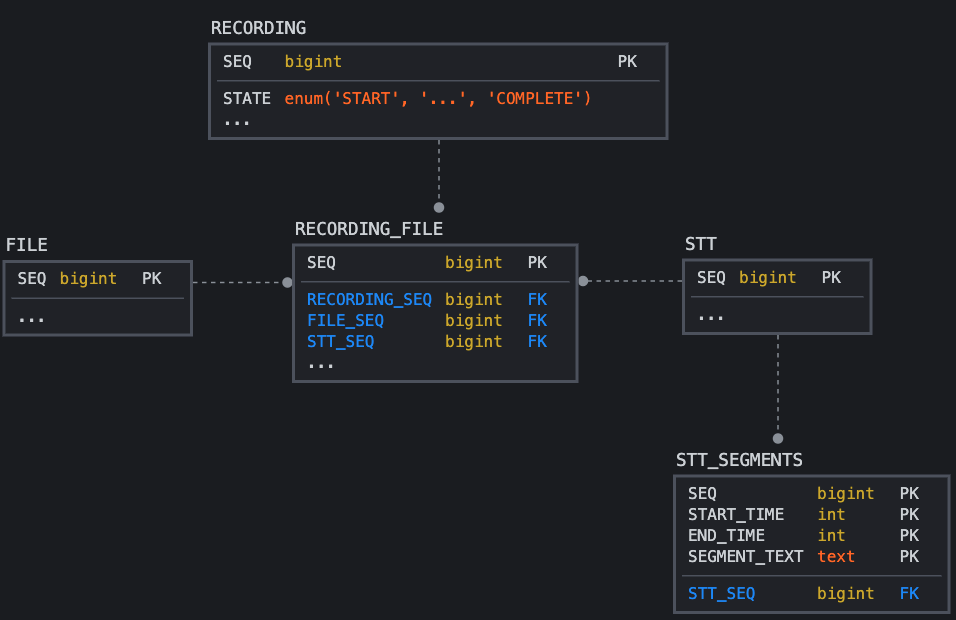
즉 각각의 오디오 파일 정보는 RECORDING_FILE 테이블에 서로 다른 튜플로 저장되며, STT API 요청도 STT 테이블에 각 튜플로 저장됩니다. 그리고 STT API 결과로 받는 텍스트 정보들도 STT_SEGMENTS 테이블에 다른 튜플로 저장됩니다.
상세 페이지 응답에 포함되는 두 오디오에 대한 STT API 결과 데이터는 테이블에서 독립적으로 존재해도 전혀 문제가 되지 않습니다. 그래서 기존에 있던 결과 데이터 생성 메서드를 재사용했고, 그 구조는 아래와 같습니다. 하지만 독립적으로 존재하는 데이터는 녹음 시간에 따라 + 어떤 화자가 + 어떤 말을 했는지를 판단해야 할 때 문제가 됩니다.
예를 들어, 두 화자 중 한 명은 ‘전문가’ 회원, 한 명은 ‘일반’ 회원일 때 아래 구조는 각 텍스트를 표현하고, 오디오와 텍스트를 연결하기에는 편한 구조입니다. 하지만 채팅 형식으로 텍스트를 보여주기 위해 어떤 시간에 + 어떤 화자가 + 어떤 말을 했는지를 찾으려면 한 문장을 출력할 때마다 알맞은 위치를 찾기 위해 expertSegment, clientSegment에 포함된 모든 segment의 시작 시간을 확인해야되는 불편함이 있습니다.
{
...
"expertSegment": {
...
"seq": 8511,
"originSegments": [
{
"start": 39260,
"end": 41060,
"text": "반갑습니다. 저는 닥톡 음성차팅 담당자입니다.",
"confidence": 0.125,
"segmentSeq": 51643
},
{
"start": 42200,
"end": 47640,
"text": "모든 대화를 기록하기란 쉽지 않은데요.",
"confidence": 0.6842105263157895,
"segmentSeq": 51644
},
...
],
...
},
"clientSegment": {
...
"seq": 8512,
"originSegments": [
{
"start": 41100,
"end": 45020,
"text": "언제 사용하면 좋은 서비스인가요",
"confidence": 0.129,
"segmentSeq": 51651
},
{
"start": 63200,
"end": 78640,
"text": "작성된 파일은 어떻게 볼 수 있나요?",
"confidence": 0.7842105263157895,
"segmentSeq": 51652
},
...
],
...
}
...
}
“어떻게 하면 프론트에서 편하게 화자별 텍스트를 출력할 수 있을까” 고민하게 되었는데요. 결론은 프론트엔드에서든 백엔드에서든 두 STT API 결과를 합쳐 오디오의 시작 시간 기준으로 정렬된 데이터가 필요하겠구나 였습니다.
그래서 두 화자의 모든 텍스트 세그먼트를 합쳐 시작 시간 순으로 정렬한 combinedSttSegment를 상세 페이지 응답 결과에 추가하게 되었습니다. combinedSttSegment의 key는 각 화자의 STT 결과 키 값인 seq이고, value는 텍스트 세그먼트의 segmentSeq 값 입니다.
{
...
"combinedSttSegment": [
{
"sttSeq": 8511,
"segmentSeq": 51643
},
{
"sttSeq": 8512,
"segmentSeq": 51651
},
{
"sttSeq": 8511,
"segmentSeq": 51644
},
{
"sttSeq": 8511,
"segmentSeq": 51645
},
{
"sttSeq": 8512,
"segmentSeq": 51652
}
],
...
}
이 응답을 받은 프론트엔드에서는 combinedSttSegment를 순차적으로 확인하면서 두 화자를 구분해 출력하면 됩니다.
const expertSegments = expertSegment.originSegments;
const clientSegments = clientSegment.originSegments;
const expertSttSeq = expertSegment.seq;
const clientSttSeq = clientSegment.seq;
for (let i = 0; i < combinedSttSegment.length; i++) {
if (combinedSttSegment[i].sttSeq === expertSttSeq) {
segment = expertSegments[combinedSttSegment[i].segmentSeq];
...
} else {
segment = clientSegments[combinedSttSegment[i].segmentSeq];
...
}
...
}
그리고 combinedSttSegment를 순차적으로 확인하면서 한 화자가 연속해서 말을 했을 때는 하나의 문단으로 묶는 작업도 이뤄집니다.

위에 보여지는 하나의 문단은 사실 여러 세그먼트로 구성된 것입니다~
추가적으로,
텍스트 수정 기능은 STT API 결과로 받은 텍스트가 정확하지 않을 경우 클라이언트가 수정할 수 있는 기능인데요. 위에서 언급했듯 하나의 문단은 여러 세그먼트로 구성될 수 있는데, 저는 각 세그먼트의 텍스트를 <input> 태그로 만들어 세그먼트 단위로 수정할 수 있도록 했습니다. 그리고 태그에 변경을 감지하는 이벤트를 추가했고, 특정 텍스트에서 수정이 발생했다는 것을 체크하는 방법으로는 간단히 배열을 사용했습니다.
// 배열 생성, 초기화
isAnyChanged = Array.from({length: combinedSttSegment.length}, (i) => false);
전체 텍스트 세그먼트 길이와 크기가 같은 isAnyChanged 배열을 생성해 초기값을 false로 설정하고, <input> 태그에 추가한 변경 이벤트가 감지될 때마다 배열에서 변경된 텍스트에 해당하는 인덱스가 참조하는 값을 true로 변경합니다(물론 실제 데이터가 변경되었는지도 당연히 체크합니다). 이 배열 정보는 사용자가 페이지를 나갈 때 사용하는 버튼의 텍스트와 css를 변경하는 부분에서 사용되었습니다.
// 텍스트가 수정되었을 때 버튼을 변경하는 메서드 호출
function changeSaveExitBtn() {
let saveExitBtn = $("#save-exit-btn");
if (isAnyChanged.includes(true)) {
saveExitBtn.text("편집하고 저장하기");
saveExitBtn.css("background-color", "#12ac00");
saveExitBtn.css("color", "#FFFFFF");
} else {
saveExitBtn.text("편집없이 나가기");
saveExitBtn.css("background-color", "#efefef");
saveExitBtn.css("color", "#707070");
}
}
마지막으로
이번 글에서는 기술적인 내용 보다는 닥톡 신규 서비스의 프론트엔드와 백엔드에 대해 전반적으로 소개해드렸습니다. 궁금하신 분이 있다면, 다음에는 미디어 서버에서 어떻게 오디오 채널 분리를 했는지에 대해 공유드리겠습니다.
여기까지 읽어주셔서 감사합니다🙇🏼♀️